![[wordcloud of Miguel Á. Carreira-Perpiñán's recent papers]](research/wordcloud/macp-2021-2022.png)
What you can find here:
This work has been funded in part by NSF, CITRIS, Google, Intel, Xilinx and NVIDIA Corporation. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation.
When available, implementations of the code (generally Matlab, Python or C/C++) and data are linked next to the corresponding paper below. If not available (particularly when it says "coming soon"), feel free to ask us and we may be able to give you some working code, even if not well documented.
Gazizov, K. and Carreira-Perpiñán, M. Á. (2025):
A faster training algorithm for regression trees with linear leaves, and an analysis of its complexity.
Advances in Neural Information Processing Systems 38 (NeurIPS 2025), to appear.
[external link] [external link2] [paper preprint] [poster] [slides] [video]
Gazizov, K., Idelbayev, Y. and Carreira-Perpiñán, M. Á. (2025):
Emerging aspects in ResNet quantization with adaptive codebook sizes.
Bay Area Machine Learning Symposium (BayLearn 2025).
[external link] [paper preprint] [slides] [poster] [video]
Chan, E., Gabidolla, M. and Carreira-Perpiñán, M. Á. (2025):
Oblique decision trees as an image model for cubist image restyling.
IEEE Int. Conf. Image Processing (ICIP 2025), pp. 1708-1713.
[external link] [paper preprint] [slides] [more slides] [video] [animations] [poster] [© IEEE]
Extended abstract Cubist-style image effects with oblique decision trees at the Bay Area Machine Learning Symposium, Oct. 10, 2024 (BayLearn 2024):
[external link] [paper preprint] [poster] [artwork video] [news article] [art gallery]
Cubist-style image effects project page and art gallery at Edric Chan's web page
Kairgeldin, R. and Carreira-Perpiñán, M. Á. (2025):
Fast image vector quantization using sparse oblique regression trees.
IEEE Int. Conf. Image Processing (ICIP 2025), pp. 1402-1407.
[external link] [paper preprint] [slides] [video] [poster] [© IEEE]
Sundaram, J. P. S., Gabidolla, M., Carreira-Perpiñán, M. Á. and Cerpa. A. (2025):
COMNETS: COst-sensitive decision trees approach to throughput optimization for Multi-radio IoT NETworkS.
30th IEEE Int. Conf. Emerging Technologies and Factory Automation (ETFA 2025), pp. 1-8.
[external link] [paper preprint] [poster] [© IEEE]
Sundaram, J. P. S., Zharmagambetov, A., Gabidolla, M., Carreira-Perpiñán, M. Á. and Cerpa. A. (2025):
MARS: Multi-radio Architecture with ML-powered Radio Selection for Mesoscale IoT Applications.
30th IEEE Int. Conf. Emerging Technologies and Factory Automation (ETFA 2025), pp. 1-8.
[external link] [paper preprint] [poster] [© IEEE]
Kairgeldin, R. and Carreira-Perpiñán, M. Á. (2025):
Neurosymbolic models based on hybrids of convolutional neural networks and decision trees.
19th Conf. Neurosymbolic Learning and Reasoning (NeSy 2025), pp. 796-813.
[external link] [external link2] [paper preprint] [slides] [poster]
Gabidolla, M. and Carreira-Perpiñán, M. Á. (2025):
Generalized additive models via direct optimization of regularized decision stump forests.
38th Int. Conf. Machine Learning (ICML 2025), pp. 18047-18061.
[external link] [external link2] [paper preprint] [poster]
Sundaram, J. P. S., Gabidolla, M., Carreira-Perpiñán, M. Á. and Cerpa, A. (2025):
COMNETS: COst-sensitive decision trees approach to throughput optimization for Multi-radio IoT NETworkS.
Unpublished manuscript, 2025, arXiv:2502.03677.
[external link] [paper preprint]
Carreira-Perpiñán, M. Á. and Gazizov, K. (2024):
The tree autoencoder model, with application to hierarchical data visualization.
Advances in Neural Information Processing Systems 37 (NeurIPS 2024), pp. 32281-32306.
[external link] [external link2] [paper preprint] [poster] [slides] [video]
Extended abstract at the Bay Area Machine Learning Symposium, Oct. 10, 2024 (BayLearn 2024):
[external link] [paper preprint] [poster]
Kairgeldin, R. and Carreira-Perpiñán, M. Á. (2024):
Bivariate decision trees: smaller, interpretable, more accurate.
ACM SIGKDD Int. Conf. on Knowledge Discovery and Data Mining (KDD 2024), pp. 1336-1347.
[external link] [paper preprint] [poster] [slides] [video]
Short version at the Workshop on Interpretable AI: Past, Present and Future (NeurIPS 2024)
[external link] [paper preprint] [poster]
Extended abstract at the Bay Area Machine Learning Symposium, Oct. 19, 2023 (BayLearn 2023):
[external link] [paper preprint] [poster]
Gabidolla, M., Zharmagambetov, A. and Carreira-Perpiñán, M. Á. (2024):
Beyond the ROC curve: classification trees using Cost-Optimal Curves, with application to imbalanced datasets.
37th Int. Conf. Machine Learning (ICML 2024), pp. 14343-14364.
[external link] [external link2] [paper preprint] [poster]
Extended abstract at the Bay Area Machine Learning Symposium, Oct. 19, 2023 (BayLearn 2023):
[external link] [paper preprint] [poster]
Kairgeldin, R., Gabidolla, M. and Carreira-Perpiñán, M. Á. (2024):
Adaptive Softmax Trees for many-class classification.
40th Conf. Uncertainty in Artificial Intelligence (UAI 2024), pp. 1825-1841.
[external link] [external link2] [paper preprint] [poster]
Extended abstract at the Bay Area Machine Learning Symposium, Oct. 10, 2024 (BayLearn 2024):
[external link] [paper preprint] [poster]
Rustenholz, L., Klemen, M., Carreira-Perpiñán, M. Á. and López-García, P. (2024):
A machine learning-based approach for solving recurrence relations and its use in cost analysis and logic programs.
Theory and Practice of Logic Programming, 24(6):1163-1207.
[external link] [paper preprint]
Also as: Aug. 29, 2024, arXiv:2405.06972
[external link] [paper preprint]
Sundaram, J. P. S., Zharmagambetov, A., Gabidolla, M., Carreira-Perpiñán, M. Á. and Cerpa, A. (2024):
MARS: Multi-radio Architecture with Radio Selection using Decision Trees for emerging mesoscale CPS/IoT applications.
Unpublished manuscript, 2024, arXiv:2409.18043.
[external link] [paper preprint]
Hada, S. S., Carreira-Perpiñán, M. Á. and Zharmagambetov, A. (2024):
Sparse oblique decision trees: a tool to understand and manipulate neural net features.
Data Mining and Knowledge Discovery, 38:2863-2902.
[external link] [paper preprint] [media article]
Many of the figures in the publisher's version are badly messed up, with wrong labels. The arXiv paper has the correct figures.
Also as: Jan. 30, 2023, arXiv:2104.02922 (original version: Apr. 7, 2021)
[external link] [paper preprint]
Short version at the Workshop on Human-Interpretable AI (KDD 2024)
[external link] [paper preprint] [poster]
Carreira-Perpiñán, M. Á. and Hada, S. S. (2023):
Inverse classification with logistic and softmax classifiers: efficient optimization.
Unpublished manuscript, 2023, arXiv:2309.08945.
[external link] [paper preprint] [Matlab implementation]
Short version at the Workshop on Beyond first order methods in machine learning systems (ICML 2020)
[external link] [paper preprint]
"Inverse classification" includes counterfactual explanations and adversarial examples. In both cases, one wants a minimal perturbation of a given input instance that changes the prediction to a desired class. We give extremely efficient algorithms for logistic regression and softmax classifiers. For logistic regression, the problem can be solved in closed form, without iterating in the high-dimensional input space. For softmax classifiers, the special structure of the Hessian makes it possible to apply Newton's method even if the input dimension is very large.
Klemen, M., Carreira-Perpiñán, M. Á. and López-García, P. (2023):
Solving recurrence relations using machine learning, with application to cost analysis.
39th Int. Conf. Logic Programming (ICLP 2023), pp. 155-168.
[external link] [paper preprint] [slides]
Gazizov, K., Zharmagambetov, A. and Carreira-Perpiñán, M. Á. (2023):
Pros and cons of soft vs hard decision trees.
Bay Area Machine Learning Symposium (BayLearn 2023).
[external link] [paper preprint] [poster]
Carreira-Perpiñán, M. Á., Gabidolla, M. and Zharmagambetov, A. (2023):
Towards better decision forests: Forest Alternating Optimization.
IEEE Conf. Computer Vision and Pattern Recognition (CVPR 2023), pp. 7589-7598.
[external link] [OpenReview] [paper preprint] [supplementary material] [animations] [poster] [slides] [© IEEE]
CVPR 2023 Art Gallery videos:
Carreira-Perpiñán, M. Á. and Hada, S. S. (2023):
Very fast, approximate counterfactual explanations for decision forests.
37th AAAI Conf. Artificial Intelligence (AAAI 2023), pp. 6935-6943.
[external link] [paper preprint] [slides] [poster] [Python implementation (coming soon)]
Longer version: Mar. 5, 2022, arXiv:2303.02883
[external link] [paper preprint]
Finding an optimal counterfactual explanation for a decision forest (such as a Random Forest or Gradient Boosting forest) is hard because the forest partitions the input space into an exponential number of regions. We propose to approximate the problem by limiting the search over the "live" regions (those actually containing data points). This is now much faster and scales to forests having many, deep trees, as needed in real-world applications. It has the added advantage that the solution found is more likely to be realistic in that it is guided towards high-density areas of the input space.
Zharmagambetov, A. and Carreira-Perpiñán, M. Á. (2022):
Semi-supervised learning with decision trees: graph Laplacian tree alternating optimization.
Advances in Neural Information Processing Systems 35 (NeurIPS 2022), pp. 2392-2405.
[external link] [external link2] [paper preprint] [supplementary material] [poster] [video]
Extended abstract at the Bay Area Machine Learning Symposium, Oct. 20, 2022 (BayLearn 2022):
[external link] [paper preprint] [poster]
Gabidolla, M. and Carreira-Perpiñán, M. Á. (2022):
Optimal interpretable clustering using oblique decision trees.
ACM SIGKDD Int. Conf. on Knowledge Discovery and Data Mining (KDD 2022), pp. 400-410.
[external link] [paper preprint] [slides] [poster]
Gabidolla, M., Zharmagambetov, A. and Carreira-Perpiñán, M. Á. (2022):
Improved multiclass AdaBoost using sparse oblique decision trees.
Int. Joint Conf. on Neural Networks (IJCNN 2022).
[external link] [paper preprint] [slides] [© IEEE]
Hada, S. S. and Carreira-Perpiñán, M. Á. (2022):
Sparse oblique decision trees: a tool to interpret natural language processing datasets.
Int. Joint Conf. on Neural Networks (IJCNN 2022).
[external link] [paper preprint] [slides] [© IEEE]
Gabidolla, M. and Carreira-Perpiñán, M. Á. (2022):
Pushing the envelope of gradient boosting forests via globally-optimized oblique trees.
IEEE Conf. Computer Vision and Pattern Recognition (CVPR 2022), pp. 285-294.
[external link] [paper preprint] [supplementary material] [poster] [slides] [© IEEE]
Idelbayev, Y. and Carreira-Perpiñán, M. Á. (2022):
Exploring the effect of l0/l2 regularization in neural network pruning using the LC toolkit.
IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP 2022), pp. 3373-3377.
[external link] [paper preprint] [slides] [poster] [Python implementation] [© IEEE]
Hada, S. S. and Carreira-Perpiñán, M. Á. (2022):
Interpretable image classification using sparse oblique decision trees.
IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP 2022), pp. 2759-2763.
[external link] [paper preprint] [slides] [poster] [© IEEE]
Zharmagambetov, A. and Carreira-Perpiñán, M. Á. (2022):
Learning interpretable, tree-based projection mappings for nonlinear embeddings.
25th Int. Conf. Artificial Intelligence and Statistics (AISTATS 2022), pp. 9550-9570.
[external link] [paper preprint] [slides] [poster] [animations] [video]
University of California Presidential Working Group on AI (2021):
Responsible Artificial Intelligence: Recommendations to Guide the University of California's Artificial Intelligence Strategy.
Final report, University of California, Oct. 2021.
[external link] [paper preprint] [press release]
Zharmagambetov, A., Gabidolla, M. and Carreira-Perpiñán, M. Á. (2021):
Softmax Tree: an accurate, fast classifier when the number of classes is large.
Conf. Empirical Methods in Natural Language Processing (EMNLP 2021), pp. 10730-10745.
[external link] [paper preprint] [slides] [poster]
Idelbayev, Y. and Carreira-Perpiñán, M. Á. (2021):
LC: A flexible, extensible open-source toolkit for model compression.
Conference on Information and Knowledge Management (CIKM 2021), resource paper, pp. 4504-4514.
[external link] [paper preprint] [slides] [Python implementation]
Idelbayev, Y. and Carreira-Perpiñán, M. Á. (2021):
More general and effective model compression via an additive combination of compressions.
32nd European. Conf. Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML/PKDD 2021), pp. 233-248.
[external link] [paper preprint] [slides] [Python implementation]
Longer version:
Carreira-Perpiñán, M. Á. and Idelbayev, Y.:
Model compression as constrained optimization, with application to neural nets. Part V: combining compressions (2021).
Unpublished manuscript, Jul. 9, 2021, arXiv:2107.04380.
[external link] [paper preprint]
Hada, S. S. and Carreira-Perpiñán, M. Á. (2021):
Exploring counterfactual explanations for classification and regression trees.
Int. Workshop and Tutorial on eXplainable Knowledge Discovery in Data Mining (at ECML 2021), pp. 489-504.
[external link] [paper preprint] [slides]
Zharmagambetov, A., Gabidolla, M. and Carreira-Perpiñán, M. Á. (2021):
Improved multiclass Adaboost for image classification: the role of tree optimization.
IEEE Int. Conf. Image Processing (ICIP 2021), pp. 424-428.
[external link] [paper preprint] [slides] [poster] [© IEEE]
Zharmagambetov, A. and Carreira-Perpiñán, M. Á. (2021):
A simple, effective way to improve neural net classification: ensembling unit activations with a sparse oblique decision tree.
IEEE Int. Conf. Image Processing (ICIP 2021), pp. 369-373.
[external link] [paper preprint] [slides] [poster] [© IEEE]
Idelbayev, Y. and Carreira-Perpiñán, M. Á. (2021):
Beyond FLOPs in low-rank compression of neural networks: optimizing device-specific inference runtime.
IEEE Int. Conf. Image Processing (ICIP 2021), pp. 2843-2847.
[external link] [paper preprint] [slides] [poster] [Python implementation] [© IEEE]
Hada, S. S. and Carreira-Perpiñán, M. Á. (2021):
Sampling the "inverse set" of a neuron.
IEEE Int. Conf. Image Processing (ICIP 2021), pp. 3712-3716.
[external link] [paper preprint] [slides] [poster] [© IEEE]
Hada, S. S., Carreira-Perpiñán, M. Á. and Zharmagambetov, A. (2021):
Understanding and manipulating neural net features using sparse oblique classification trees.
IEEE Int. Conf. Image Processing (ICIP 2021), pp. 3707-3711.
[external link] [paper preprint] [slides] [poster] [© IEEE]
Zharmagambetov, A., Hada, S. S., Gabidolla, M. and Carreira-Perpiñán, M. Á. (2021):
Non-greedy algorithms for decision tree optimization: an experimental comparison.
Int. Joint Conf. on Neural Networks (IJCNN 2021).
[external link] [paper preprint] [slides] [© IEEE]
Older version: "An experimental comparison of old and new decision tree algorithms", Mar. 20, 2020, arXiv:1911.03054
[external link] [paper preprint]
Zharmagambetov, A., Gabidolla, M. and Carreira-Perpiñán, M. Á. (2021):
Improved boosted regression forests through non-greedy tree optimization.
Int. Joint Conf. on Neural Networks (IJCNN 2021).
[external link] [paper preprint] [slides] [© IEEE]
Idelbayev, Y. and Carreira-Perpiñán, M. Á. (2021):
An empirical comparison of quantization, pruning and low-rank neural network compression using the LC toolkit.
Int. Joint Conf. on Neural Networks (IJCNN 2021).
[external link] [paper preprint] [slides] [Python implementation] [© IEEE]
Idelbayev, Y., Molchanov, P., Shen, M., Yin, H., Carreira-Perpiñán, M. Á. and Alvarez, J. M. (2021):
Optimal quantization using scaled codebook.
IEEE Conf. Computer Vision and Pattern Recognition (CVPR 2021), pp. 12090-12099.
[external link] [paper preprint] [slides] [poster] [© IEEE]
Idelbayev, Y. and Carreira-Perpiñán, M. Á. (2021):
Optimal selection of matrix shape and decomposition scheme for neural network compression.
IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP 2021), pp. 3250-3254.
[external link] [paper preprint] [slides] [Python implementation] [© IEEE]
Zharmagambetov, A. and Carreira-Perpiñán, M. Á. (2021):
Learning a tree of neural nets.
IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP 2021), pp. 3140-3144.
[external link] [paper preprint] [slides] [© IEEE]
Idelbayev, Y. and Carreira-Perpiñán, M. Á. (2021):
Neural network compression via additive combination of reshaped, low-rank matrices.
Data Compression Conference (DCC 2021), pp. 243-252.
[external link] [paper preprint] [slides] [Python implementation] [© IEEE]
Carreira-Perpiñán, M. Á. and Hada, S. S. (2021):
Counterfactual explanations for oblique decision trees: exact, efficient algorithms.
35th AAAI Conf. Artificial Intelligence (AAAI 2021), pp. 6903-6911.
[external link] [paper preprint] [slides] [poster] [Python implementation (coming soon)]
Longer version: Mar. 1, 2021, arXiv:2103.01096
[external link] [paper preprint]
Hada, S. S. and Carreira-Perpiñán, M. Á. (2021):
Style transfer by rigid alignment in neural net feature space.
IEEE Winter Conf. Applications of Computer Vision (WACV 2021), pp. 2575-2584.
[external link] [paper preprint] [supplementary material] [slides] [animations] [Python implementation]
Longer version: Dec. 24, 2020, arXiv:1909.13690 (v1: Sep. 27, 2019)
[external link] [paper preprint]
Gabidolla, M., Zharmagambetov, A. and Carreira-Perpiñán, M. Á. (2020):
Boosted sparse oblique decision trees.
Bay Area Machine Learning Symposium (BayLearn 2020).
[external link] [paper preprint] [video]
Idelbayev, Y. and Carreira-Perpiñán, M. Á. (2020):
A flexible, extensible software framework for model compression based on the LC algorithm.
Unpublished manuscript, May 15, 2020, arXiv:2005.07786.
[external link] [paper preprint] [Python implementation]
Short version at the 2nd On-Device Intelligence Workshop (MLSys 2021)
[external link] [paper preprint] [slides] [video]
Extended abstract at the Bay Area Machine Learning Symposium, Oct. 15, 2020 (BayLearn 2020).
[external link] [paper preprint] [video]
Carreira-Perpiñán, M. Á. and Zharmagambetov, A. (2020):
Ensembles of bagged TAO trees consistently improve over random forests, AdaBoost and gradient boosting.
ACM-IMS Foundations of Data Science Conf. (FODS 2020), pp. 35-46.
[external link] [paper preprint] [slides]
Zharmagambetov, A. and Carreira-Perpiñán, M. Á. (2020):
Smaller, more accurate regression forests using tree alternating optimization.
37th Int. Conf. Machine Learning (ICML 2020), pp. 11398-11408.
[external link] [paper preprint] [slides] [supplementary material] [video]
Idelbayev, Y. and Carreira-Perpiñán, M. Á. (2020):
Low-rank compression of neural nets: learning the rank of each layer.
IEEE Conf. Computer Vision and Pattern Recognition (CVPR 2020), pp. 8046-8056.
[external link] [paper preprint] [poster] [supplementary material] [Python implementation] [© IEEE]
Eban, E., Movshovitz-Attias, Y., Wu, H., Poon, A., Sandler, M., Idelbayev, Y. and Carreira-Perpiñán, M. Á. (2020):
Structured multi-hashing for model compression.
IEEE Conf. Computer Vision and Pattern Recognition (CVPR 2020), pp. 11900-11909.
[external link] [paper preprint] [© IEEE]
Winkler, D. A., Carreira-Perpiñán, M. Á. and Cerpa, A. E. (2020):
OPTICS: OPTimizing Irrigation Control at Scale.
ACM Trans. Sensor Networks, 16(3):22.1-22.38.
[external link] [paper preprint]
Hada, S. S. and Carreira-Perpiñán, M. Á. (2019):
Sampling the "inverse set" of a neuron: an approach to understanding neural nets.
Unpublished manuscript, Sep. 27, 2019, arXiv:1910.04857.
[external link] [paper preprint]
Extended abstract at the Bay Area Machine Learning Symposium, Oct. 11, 2018 (BayLearn 2018).
[external link] [paper preprint] [poster]
Winkler, D. A., Wang, R., Blanchette, F., Carreira-Perpiñán, M. Á. and Cerpa, A. E. (2019):
DICTUM: Distributed Irrigation aCtuation with Turf hUmidity Modeling.
ACM Trans. Sensor Networks, 15(4):41.1-41.33.
[external link] [paper preprint]
Carreira-Perpiñán, M. Á. and Alizadeh, M. (2019):
ParMAC: distributed optimisation of nested functions, with application to learning binary autoencoders.
Proc. Machine Learning and Systems 1 (MLSys 2019), pp. 276-288.
[external link] [paper preprint] [slides] [poster] [C/C++/MPI implementation] [video]
Longer version: May 30, 2016, arXiv:1605.09114
[external link] [paper preprint] [slides] [C/C++/MPI implementation]
Extended abstract at the Bay Area Machine Learning Symposium, Oct. 22, 2015 (BayLearn 2015):
Distributed optimization of binary autoencoders using auxiliary coordinates.
[external link] [paper preprint] [poster]
This proposes a parallel, distributed optimisation model for the method of auxiliary coordinates (MAC) and implements it in MPI to learn binary autoencoders. We give theoretical conditions for the parallel speedup to be nearly perfect and verify them experimentally in a computer cluster.
Carreira-Perpiñán, M. Á. and Tavallali, P. (2018):
Alternating optimization of decision trees, with application to learning sparse oblique trees.
Advances in Neural Information Processing Systems 31 (NeurIPS 2018), pp. 1211-1221.
[external link] [paper preprint] [supplementary material] [poster] [Matlab implementation (coming soon)]
Carreira-Perpiñán, M. Á. and Zharmagambetov, A. (2018):
Fast model compression.
Bay Area Machine Learning Symposium (BayLearn 2018).
[external link] [paper preprint] [poster]
Carreira-Perpiñán, M. Á. and Idelbayev, Y. (2018):
"Learning-compression" algorithms for neural net pruning.
IEEE Conf. Computer Vision and Pattern Recognition (CVPR 2018), pp. 8532-8541.
[external link] [paper preprint] [poster] [supplementary material] [Python implementation] [Python implementation (old version)] [© IEEE]
Longer version: , arXiv:
[external link] [paper preprint]
Winkler, D. A., Carreira-Perpiñán, M. Á. and Cerpa, A. E. (2018):
Plug-and-play irrigation control at scale.
17th Int. Conf. Information Processing in Sensor Networks (IPSN 2018), pp. 1-12.
[external link] [paper preprint] [slides]
Carreira-Perpiñán, M. Á. and Idelbayev, Y. (2017):
Model compression as constrained optimization, with application to neural nets. Part II: quantization.
Unpublished manuscript, Jul. 13, 2017, arXiv:1707.04319.
[external link] [paper preprint] [Python implementation]
Short version at the Workshop on Optimization for Machine Learning (NIPS 2017)
[external link] [paper preprint] [poster]
Short version at the Workshop on Machine Learning on the Phone and other Consumer Devices (NIPS 2017)
[external link] [paper preprint] [poster]
Extended abstract at the Bay Area Machine Learning Symposium, Oct. 19, 2017 (BayLearn 2017)
[external link] [paper preprint] [slides] [video]
Carreira-Perpiñán, M. Á. (2017):
Model compression as constrained optimization, with application to neural nets. Part I: general framework.
Unpublished manuscript, Jul. 5, 2017, arXiv:1707.01209.
[external link] [paper preprint] [Python implementation]
This approaches the problem of model compression from an optimization point of view and introduces 1) a generic model compression as constrained optimization framework, and 2) a learning-compression (LC) algorithm to solve it that is simple, efficient and convergent to a local optimum (under some assumptions). It allows one to build model compression algorithms for a variety of combinations of loss function, model and compression technique, by simply reusing existing code from signal compression and machine learning as a black box.
Carreira-Perpiñán, M. Á. and Raziperchikolaei, R. (2017):
Learning supervised binary hashing without binary code optimization.
Workshop on Nearest Neighbors for Modern Applications with Massive Data (NIPS 2017).
[external link] [paper preprint] [poster]
Extended abstract at the Bay Area Machine Learning Symposium, Oct. 19, 2017 (BayLearn 2017).
[external link] [paper preprint] [poster]
Raziperchikolaei, R. and Carreira-Perpiñán, M. Á. (2017):
Learning supervised binary hashing: optimization vs diversity.
IEEE Int. Conf. Image Processing (ICIP 2017), pp. 3695-3699.
[external link] [paper preprint] [poster]
Raziperchikolaei, R. and Carreira-Perpiñán, M. Á. (2017):
Learning circulant support vector machines for fast image search.
IEEE Int. Conf. Image Processing (ICIP 2017), pp. 385-389.
[external link] [paper preprint] [slides] [Matlab implementation (coming soon)]
Short version at the Workshop on Optimization for Machine Learning (NIPS 2017)
[external link] [paper preprint] [poster]
Vladymyrov, M. and Carreira-Perpiñán, M. Á. (2017):
Fast, accurate spectral clustering using locally linear landmarks.
Int. Joint Conf. Neural Networks (IJCNN 2017), pp. 3870-3879.
[external link] [paper preprint]
Raziperchikolaei, R. and Carreira-Perpiñán, M. Á. (2016):
Learning independent, diverse binary hash functions: pruning and locality.
17th IEEE Int. Conf. Data Mining (ICDM 2016), pp. 1173-1178.
[external link] [paper preprint] [slides] [Matlab implementation]
Carreira-Perpiñán, M. Á. and Raziperchikolaei, R. (2016):
An ensemble diversity approach to supervised binary hashing.
Advances in Neural Information Processing Systems 29 (NIPS 2016), pp. 757-765.
[external link] [paper preprint] [supplementary material] [poster] [Matlab implementation]
Longer version: Feb. 3, 2016, arXiv:1602.01557
[external link] [paper preprint]
Extended abstract at the Bay Area Machine Learning Symposium, Oct. 22, 2015 (BayLearn 2015):
[external link] [paper preprint] [slides] [video]
This shows that competitive binary hash functions (whose output is a vector of binary values) can be learned independently by simply making them differ through ensemble diversity techniques. This is far faster and scalable than solving a joint optimisation problem where all bits are coupled.
Raziperchikolaei, R. and Carreira-Perpiñán, M. Á. (2016):
Optimizing affinity-based binary hashing using auxiliary coordinates.
Advances in Neural Information Processing Systems 29 (NIPS 2016), pp. 640-648.
[external link] [paper preprint] [supplementary material] [poster] [Matlab implementation]
Longer version: Feb. 5, 2016, arXiv:1501.05352
[external link] [paper preprint]
Short version at the Workshop on Non-Convex Analysis and Optimization (ICML 2016):
[external link] [paper preprint] [poster]
Extended abstract at the Bay Area Machine Learning Symposium, Oct. 6, 2016 (BayLearn 2016):
[external link] [paper preprint] [poster]
This uses the method of auxiliary coordinates (MAC) to learn an arbitrary binary hash function (i.e., a function whose output is a vector of binary values) with an arbitrary affinity-based loss function.
Vladymyrov, M. and Carreira-Perpiñán, M. Á. (2016):
The Variational Nyström method for large-scale spectral problems.
33rd Int. Conf. Machine Learning (ICML 2016), pp. 211-220.
[external link] [paper preprint] [supplementary material] [slides] [poster] [Matlab implementation]
Winkler, D. A., Wang, R., Blanchette, F., Carreira-Perpiñán, M. Á. and Cerpa, A. E. (2016):
MAGIC: Model-Based Actuation for Ground Irrigation Control.
15th Int. Conf. Information Processing in Sensor Networks (IPSN 2016), article No. 9.
[external link] [paper preprint] [slides]
Poster abstract at the 13th ACM Conf. Embedded Networked Sensor Systems (SenSys 2015):
MICO: Model-Based Irrigation Control Optimization, pp. 409-410
[external link] [paper preprint]
Carreira-Perpiñán, M. Á. and M. Vladymyrov (2015):
A fast, universal algorithm to learn parametric nonlinear embeddings.
Advances in Neural Information Processing Systems 28 (NIPS 2015), pp. 253-261.
[external link] [paper preprint] [supplementary material] [poster] [Matlab implementation (coming soon)]
Extended abstract at the Bay Area Machine Learning Symposium, Oct. 21, 2014 (BayLearn 2014):
[external link] [paper preprint] [poster]
This uses the method of auxiliary coordinates (MAC) to learn an optimal mapping (such as linear or a neural net) for a nonlinear embedding (such as the elastic embedding or t-SNE).
Carreira-Perpiñán, M. Á. (2015):
Clustering methods based on kernel density estimators: mean-shift algorithms.
Invited chapter in Handbook of Cluster Analysis (C. Hennig, M. Meila, F. Murtagh and R. Rocci, eds.), CRC/Chapman and Hall, chapter 18, pp. 383-418.
[external link] [paper preprint]
Preprint version:
Carreira-Perpiñán, M. Á. (2015):
A review of mean-shift algorithms for clustering.
Unpublished manuscript, Mar. 2, 2015, arXiv:1503.00687.
[external link] [paper preprint]
This contains a review of mean-shift algorithms, mostly for nonparametric clustering but also for problems such as manifold denoising and multivalued regression (modal regression). It also discusses relations with scale-space theory, spectral clustering and K-modes algorithms, as well as theoretical results about mean-shift algorithms and the geometry of modes of kernel density estimators and Gaussian mixtures.
Archambault, D., Bunte, K. Carreira-Perpiñán, M. Á., Ebert, D., Ertl, T. and Zupan, B. (2015):
Machine learning meets visualization: a roadmap for scalable data analytics.
In Bridging Information Visualization with Machine Learning (D. A. Keim, T. Munzner, F. Rossi and M. Verleysen, eds.), Dagstuhl Reports 5(3):8-12.
[external link] [paper preprint]
Carreira-Perpiñán, M. Á. and Raziperchikolaei, R. (2015):
Hashing with binary autoencoders.
IEEE Conf. Computer Vision and Pattern Recognition (CVPR 2015), pp. 557-566.
[external link] [paper preprint] [slides] [poster] [Matlab implementation] [Weka implementation]
Longer version: Jan. 5, 2015, arXiv:1501.00756
[external link] [paper preprint] [slides]
Extended abstract at the Bay Area Machine Learning Symposium, Oct. 21, 2014 (BayLearn 2014):
[external link] [paper preprint] [slides] [poster]
Workshop paper at the 2015 INFORMS Workshop on Data Mining and Analytics:
[external link] [paper preprint] [slides]
Short version at the Workshop on Optimization Methods for the Next Generation of Machine Learning (ICML 2016):
Optimizing binary autoencoders using auxiliary coordinates, with application to learning binary hashing
[external link] [paper preprint] [poster]
This uses the method of auxiliary coordinates (MAC) to learn an autoencoder with binary hidden units, whose encoder gives good binary hash functions for image retrieval.
Carreira-Perpiñán, M. Á. (2014):
An ADMM algorithm for solving a proximal bound-constrained quadratic program.
Unpublished manuscript, Dec. 29, 2014, arXiv:1412.8493 [math.OC].
[external link] [paper preprint] [Matlab implementation]
Wang, W. and Carreira-Perpiñán, M. Á. (2014):
The Laplacian K-modes algorithm for clustering.
Unpublished manuscript, Jun. 15, 2014, arXiv:1406.3895.
[external link] [paper preprint] [slides] [animations] [Matlab implementation]
Wang, W. and Carreira-Perpiñán, M. Á. (2014):
The role of dimensionality reduction in classification.
28th AAAI Conference on Artificial Intelligence (AAAI 2014), pp. 2128-2134.
[external link] [paper preprint] [slides] [poster] [animations] [Matlab implementation] [Weka implementation]
Longer version:
Wang, W. and Carreira-Perpiñán, M. Á.:
The role of dimensionality reduction in classification (2014).
Unpublished manuscript, May 25, 2014, arXiv:1405.6444.
[external link] [paper preprint]
This uses the method of auxiliary coordinates (MAC) to learn nonlinear, low-dimensional features for a linear SVM. It also describes (possibly for the first time) the phenomenon of "neural collapse" popularised more recently in the neural networks literature, namely that the activations prior to a linear classifier layer collapse into point-like clusters arranged as the vertices of a simplex-like configuration. Specifically, we considered a composition y = g(F(x)) of a nonlinear, infinitely flexible mapping F and a K-class linear classifier g. When jointly training F and g to optimise a classification loss, the L-dimensional outputs of F (called auxiliary coordinates in our paper) would cluster the training points of each class onto a single centroid, and these K centroids would form an optimal geometrical arrangement, as follows:
This presentation (slides 51-61) considers logistic regression besides a linear SVM as classifier g.
Carreira-Perpiñán, M. Á. and Wang, W. (2014):
LASS: a simple assignment model with Laplacian smoothing.
28th AAAI Conference on Artificial Intelligence (AAAI 2014), pp. 1715-1721.
[external link] [paper preprint] [slides] [poster] [Matlab implementation]
Longer version:
Carreira-Perpiñán, M. Á. and Wang, W.:
LASS: a simple assignment model with Laplacian smoothing (2014).
Unpublished manuscript, May 22, 2014, arXiv:1405.5960.
[external link] [paper preprint]
Extended abstract at the Bay Area Machine Learning Symposium, Aug. 28, 2013 (BayLearn 2013):
A simple assignment model with Laplacian smoothing
[external link] [paper preprint] [poster]
LASS learns soft assignments of N items to K categories, given sparse similarity information between items, and between items and categories (as e.g. in image or document tagging). It can be seen as semi-supervised learning of assignments or probability distributions.
Carreira-Perpiñán, M. Á. and Wang, W. (2014):
Distributed optimization of deeply nested systems.
17th Int. Conf. Artificial Intelligence and Statistics (AISTATS 2014), pp. 10-19.
Notable paper award (even more interesting, this paper was rejected twice from NIPS and twice from ICML).
[external link] [paper preprint] [supplementary material] [slides] [video] [poster] [Matlab implementation (coming soon)]
Longer version:
Carreira-Perpiñán, M. Á. and Wang, W.:
Distributed optimization of deeply nested systems (2012).
Unpublished manuscript, Dec. 24, 2012, arXiv:1212.5921.
[external link] [paper preprint]
Extended abstract at the Bay Area Machine Learning Symposium, Aug. 30, 2012 (BayLearn 2012):
Fast algorithms for learning deep neural networks
[external link] [paper preprint] [slides] [poster]
This introduces a new, general mathematical technique, the method of auxiliary coordinates (MAC), to train deep nets and other "nested" systems. It results in a coordination-minimisation (CM) algorithm that alternates training individual layers (reusing existing algorithms) with glueing layers (using auxiliary coordinates). It is provably convergent, simple to implement, has embarrassing parallelism within each step, and can apply even if derivatives are not available. It can also do model selection "on the fly" and search over architectures while it trains.
Vladymyrov, M. and Carreira-Perpiñán, M. Á. (2014):
Linear-time training of nonlinear low-dimensional embeddings.
17th Int. Conf. Artificial Intelligence and Statistics (AISTATS 2014), pp. 968-977.
[external link] [paper preprint] [supplementary material] [slides] [poster] [Matlab implementation]
Extended abstract at the Bay Area Machine Learning Symposium, Aug. 28, 2013 (BayLearn 2013):
Linear-time training of nonlinear low-dimensional embeddings
[external link] [paper preprint] [poster]
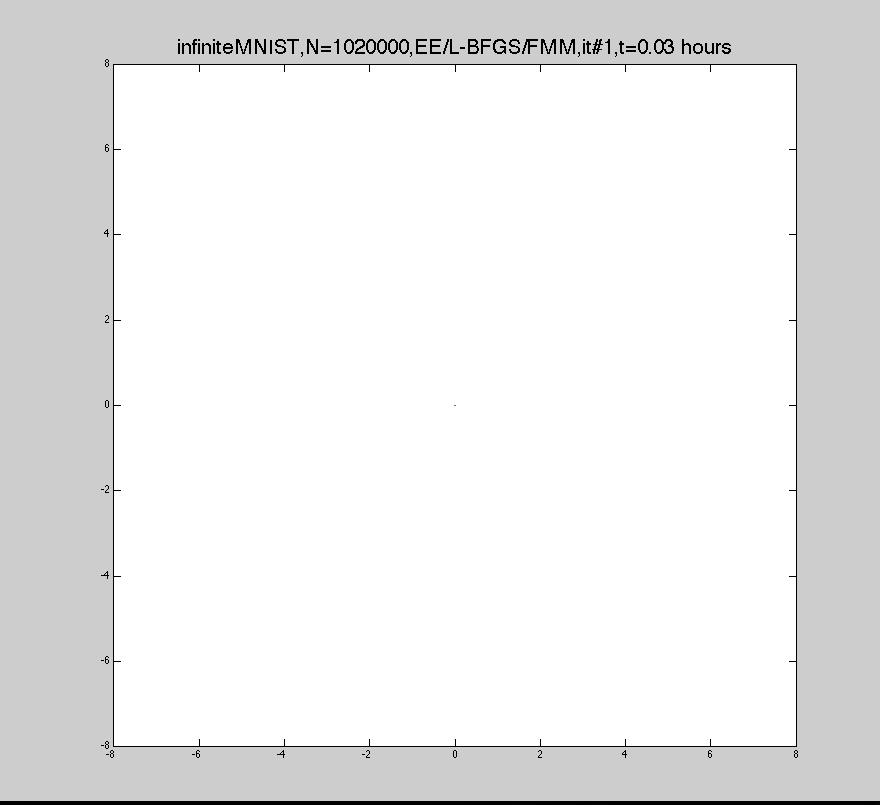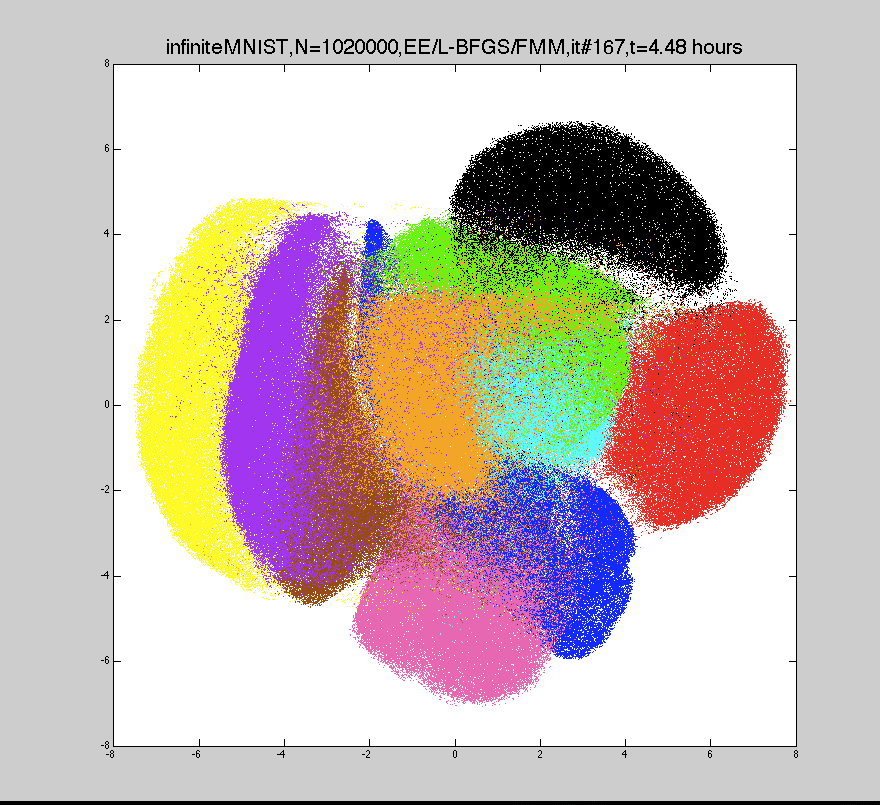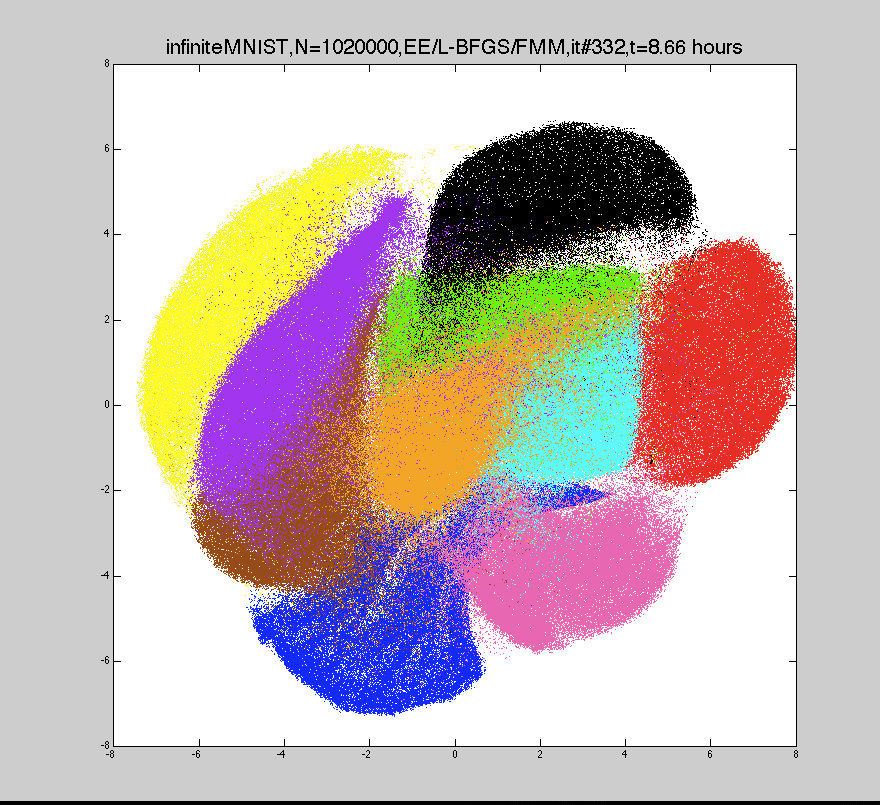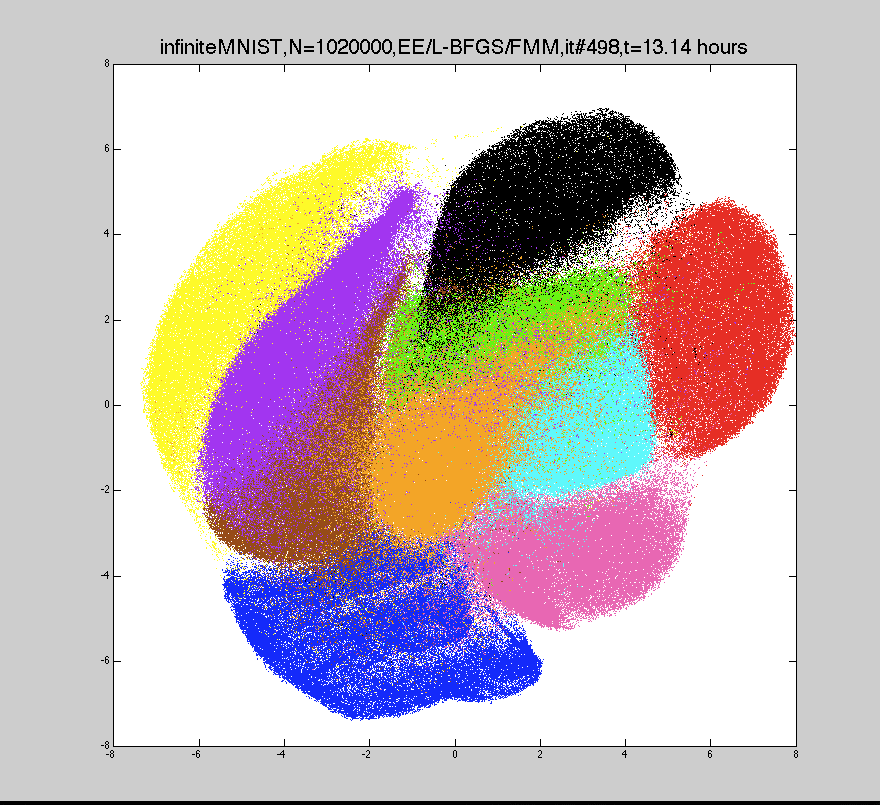
This uses fast multipole methods to approximate the gradient computation in linear time, so we can train embeddings with millions of points in a few hours.
Erickson, V., Carreira-Perpiñán, M. Á. and Cerpa, A. E. (2014):
Occupancy modeling and prediction for building energy management.
ACM Trans. Sensor Networks, 10(3):42.1-42.28.
[external link] [paper preprint]
Wang, W. and Carreira-Perpiñán, M. Á. (2013):
Projection onto the probability simplex: an efficient algorithm with a simple proof, and an application.
Unpublished manuscript, Sep. 3, 2013, arXiv:1309.1541.
[external link] [paper preprint] [Matlab implementation]
Vladymyrov, M. and Carreira-Perpiñán, M. Á. (2013):
Locally Linear Landmarks for large-scale manifold learning.
24th European. Conf. Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML/PKDD 2013), pp. 256-271.
[external link] [paper preprint] [slides] [poster] [Matlab implementation]
Short version at the Workshop on Spectral Learning (ICML 2013):
[external link] [paper preprint] [poster]
LLL is a fast, approximate method to solve spectral dimensionality reduction problems such as Laplacian eigenmaps. It is faster than the Nyström formula while giving more accurate results.
Vladymyrov, M. and Carreira-Perpiñán, M. Á. (2013):
Entropic affinities: properties and efficient numerical computation.
30th Int. Conf. Machine Learning (ICML 2013), pp. 477-485.
[external link] [paper preprint] [supplementary material] [slides] [video] [poster] [Matlab implementation]
The entropic affinities (introduced by Hinton and Roweis, NIPS 2002) are a way to construct Gaussian affinities with an adaptive bandwidth for each data point, so that each point has a fixed effective number of neighbours (perplexity) K. As we show, they can be computed efficiently. They work better than using a global bandwidth for all points in problems such as nonlinear embeddings, spectral clustering, etc.
Kamthe, A., Carreira-Perpiñán, M. Á. and Cerpa, A. E. (2013):
Improving wireless link simulation using multi-level Markov models.
ACM Trans. Sensor Networks 10(1):17.1-17.28.
[external link] [paper preprint] [TOSSIM code for TinyOS 2.0]
Carreira-Perpiñán, M. Á. and Wang, W. (2013):
The K-modes algorithm for clustering.
Unpublished manuscript, Apr. 23, 2013, arXiv:1304.6478.
[external link] [paper preprint] [slides] [Matlab implementation]
Kamthe, A., Carreira-Perpiñán, M. Á. and Cerpa, A. E. (2013):
Quick construction of data-driven models of the short-term behavior of wireless links.
32nd Annual IEEE Int. Conf. Computer Communications (INFOCOM 2013) Mini-Conference, 160-164.
[external link] [paper preprint] [slides]
Vladymyrov, M. and Carreira-Perpiñán, M. Á. (2012):
Partial-Hessian strategies for fast learning of nonlinear embeddings.
29th Int. Conf. Machine Learning (ICML 2012), pp. 345-352.
[external link] [paper preprint] [supplementary material] [slides] [video] [poster] [Matlab implementation] [R implementation by James Melville]
Extended abstract at the Bay Area Machine Learning Symposium, Aug. 30, 2012 (BayLearn 2012):
Fast training of graph-based algorithms for nonlinear dimensionality reduction
[external link] [paper preprint] [slides]
This introduces the spectral direction, a fast optimisation method for nonlinear embedding methods. This code is the fastest one available for EE, SNE and t-SNE as far as I know.
Wang, W. and Carreira-Perpiñán, M. Á. (2012):
Nonlinear low-dimensional regression using auxiliary coordinates.
15th Int. Conf. Artificial Intelligence and Statistics (AISTATS 2012), pp. 1295-1304.
[external link] [paper preprint] [poster] [animations] [Matlab implementation (coming soon)]
Farhadloo, M. and Carreira-Perpiñán, M. Á. (2012):
Learning and adaptation of a tongue shape model with missing data.
IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP 2012), pp. 3981-3984.
[external link] [paper preprint] [slides] [Matlab implementation (coming soon)] [© IEEE]
Farhadloo, M. and Carreira-Perpiñán, M. Á. (2012):
Regularising an adaptation algorithm for tongue shape models.
IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP 2012), pp. 4481-4484.
[external link] [paper preprint] [poster] [Matlab implementation (coming soon)] [© IEEE]
Wang, W., Carreira-Perpiñán, M. Á. and Lu, Z. (2011):
A denoising view of matrix completion.
Advances in Neural Information Processing Systems 24 (NIPS 2011), pp. 334-342.
[external link] [paper preprint] [poster] [animations] [Matlab implementation]
Carreira-Perpiñán, M. Á. and Lu, Z. (2011):
Manifold learning and missing data recovery through unsupervised regression.
12th IEEE Int. Conf. Data Mining (ICDM 2011), pp. 1014-1019.
[external link] [paper preprint] [slides] [animations] [Matlab implementation] [© IEEE]
Kamthe, A., Erickson, V., Carreira-Perpiñán, M. Á. and Cerpa, A. E. (2011):
Enabling building energy auditing using adapted occupancy models.
3rd ACM Workshop on Embedded Sensing Systems for Energy-Efficiency in Buildings (BuildSys 2011), pp. 31-36.
[external link] [paper preprint] [slides]
Kamthe, A., Carreira-Perpiñán, M. Á. and Cerpa, A. E. (2011):
Adaptation of a mixture of multivariate Bernoulli distributions.
22nd Int. Joint Conf. Artificial Intelligence (IJCAI 2011), pp. 1336-1341.
[external link] [paper preprint] [poster] [Matlab implementation (coming soon)]
Erickson, V., Carreira-Perpiñán, M. Á. and Cerpa, A. E. (2011):
OBSERVE: Occupancy-Based System for Efficient Reduction of HVAC Energy.
10th Int. Conf. Information Processing in Sensor Networks (IPSN 2011), pp. 258-269.
[external link] [paper preprint] [slides] [poster]
Carreira-Perpiñán, M. Á. (2011):
Machine learning models of the tongue shape during speech.
9th Int. Seminar on Speech Production (ISSP 2011), pp. 103-110.
[external link.] [paper preprint] [poster]
Qin, C., Carreira-Perpiñán, M. Á. and Farhadloo, M. (2010):
Adaptation of a tongue shape model by local feature transformations.
Interspeech 2010, pp. 1596-1599.
[external link] [paper preprint] [poster] [Matlab implementation (coming soon)]
Qin, C. and Carreira-Perpiñán, M. Á. (2010):
Estimating missing data sequences in X-ray microbeam recordings.
Interspeech 2010, pp. 1592-1595.
[external link] [paper preprint] [poster] [Matlab implementation]
The preprint fixes a typo in the 3rd eq. of p. 2.
Qin, C. and Carreira-Perpiñán, M. Á. (2010):
Articulatory inversion of American English /r/ by conditional density modes.
Interspeech 2010, pp. 1998-2001.
[external link] [paper preprint] [slides] [animations]
Xie, L., Carreira-Perpiñán, M. Á. and Newsam, S. (2010):
Semi-supervised regression with temporal image sequences.
IEEE Int. Conf. Image Processing (ICIP 2010), pp. 2637-2640.
[external link] [paper preprint] [slides] [© IEEE]
Carreira-Perpiñán, M. Á. (2010):
The elastic embedding algorithm for dimensionality reduction.
27th Int. Conf. Machine Learning (ICML 2010), pp. 167-174.
[external link] [paper preprint] [supplementary material] [slides] [poster] [Matlab implementation]
Note: the code in the link above (which uses a fixed-point iteration method) has been superseded by a faster one based on the spectral direction iteration; see the newer code from the paper by Vladymyrov and Carreira-Perpiñán, ICML 2012.
Third-party implementations: D-EE, NeuralEE.
Wang, W. and Carreira-Perpiñán, M. Á. (2010):
Manifold blurring mean shift algorithms for manifold denoising.
IEEE Conf. Computer Vision and Pattern Recognition (CVPR 2010), pp. 1759-1766.
[external link] [paper preprint] [slides] [video] [poster] [animations] [Matlab implementation (coming soon)] [© IEEE]
Carreira-Perpiñán, M. Á. and Lu, Z. (2010):
Parametric dimensionality reduction by unsupervised regression.
IEEE Conf. Computer Vision and Pattern Recognition (CVPR 2010), pp. 1895-1902.
[external link] [paper preprint] [video] [poster] [animations] [Matlab implementation] [© IEEE]
Qin, C. and Carreira-Perpiñán, M. Á. (2010):
Reconstructing the full tongue contour from EMA/X-ray microbeam.
IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP 2010), pp. 4190-4193.
[external link] [paper preprint] [slides] [animations] [Matlab implementation (coming soon)] [© IEEE]
Massaro, D. A., Carreira-Perpiñán, M. Á. and D. J. Merrill (2010):
An automatic visible speech supplement for deaf individuals' speech comprehension in face-to-face and classroom situations.
In Cued Speech and Cued Language Development of Deaf and Hard of Hearing Children (C. LaSasso, K. Lamar Crain and J. Leybaert, eds.), Plural Publishing, chapter 22, pp. 503-530.
[external link] [paper preprint]
Qin, C. and Carreira-Perpiñán, M. Á. (2009):
The geometry of the articulatory region that produces a speech sound.
Invited paper, 43rd Annual Asilomar Conf. Signals, Systems, and Computers, pp. 1742-1746.
[external link] [paper preprint] [slides] [© IEEE]
Qin, C. and Carreira-Perpiñán, M. Á. (2009):
Adaptation of a predictive model of tongue shapes.
Interspeech 2009, pp. 772-775.
[external link] [paper preprint] [poster]
Kamthe, A., Carreira-Perpiñán, M. Á. and Cerpa, A. E. (2009):
M&M: Multi-level Markov model for wireless link simulations.
7th ACM Conf. Embedded Networked Sensor Systems (SenSys 2009), pp. 57-70.
[external link] [paper preprint] [slides] [poster] [TOSSIM code for TinyOS 2.0]
Poster Abstract: Wireless link simulations using multi-level Markov models, pp. 391-392.
[external link] [paper preprint]
Massaro, D. A., Carreira-Perpiñán, M. Á. and D. J. Merrill (2009):
Optimizing visual feature perception for an automatic wearable speech supplement in face-to-face communication and classroom situations.
42st Hawaii Int. Conf. Systems Science (HICSS-42 2009), pp. 1-10.
[external link] [paper preprint] [© IEEE]
Massaro, D. A., Carreira-Perpiñán, M. Á., D. J. Merrill, C. Sterling, S. Bigler, E. Piazza and M. Perlman (2008):
iGlasses: an automatic wearable speech supplement in face-to-face communication and classroom situations (demonstration paper).
Int. Conf. Multimodal Interfaces (ICMI 2008), pp. 197-198.
[external link] [paper preprint]
Qin, C., Carreira-Perpiñán, M. Á., Richmond, K., Wrench, A. and Renals, S. (2008):
Predicting tongue shapes from a few landmark locations.
Interspeech 2008, pp. 2306-2309.
[external link] [paper preprint] [slides]
Carreira-Perpiñán, M. Á. and Lu, Z. (2008):
Dimensionality reduction by unsupervised regression.
IEEE Conf. Computer Vision and Pattern Recognition (CVPR 2008).
[external link] [paper preprint] [slides] [poster] [animations] [Matlab implementation] [© IEEE]
The preprint fixes three errata in the legends of fig. 2.
Carreira-Perpiñán, M. Á. (2008):
Generalised blurring mean-shift algorithms for nonparametric clustering.
IEEE Conf. Computer Vision and Pattern Recognition (CVPR 2008).
[external link] [paper preprint] [poster] [animations] [© IEEE]
Lu, Z. and Carreira-Perpiñán, M. Á. (2008):
Constrained spectral clustering through affinity propagation.
IEEE Conf. Computer Vision and Pattern Recognition (CVPR 2008).
[external link] [paper preprint] [poster] [Matlab implementation] [© IEEE]
Qin, C. and Carreira-Perpiñán, M. Á. (2008):
Trajectory inverse kinematics by conditional density modes.
IEEE Int. Conf. on Robotics and Automation (ICRA 2008), pp. 1979-1986.
[external link] [paper preprint] [slides] [poster] [animations] [© IEEE]
Qin, C. and Carreira-Perpiñán, M. Á. (2008):
Trajectory inverse kinematics by nonlinear, nongaussian tracking.
IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP 2008), pp. 2057-2060.
[external link] [paper preprint] [poster] [© IEEE]
Özertem, U., Erdogmus, D. and Carreira-Perpiñán, M. Á. (2008):
Density geodesics for similarity clustering.
IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP 2008), pp. 1977-1980.
[external link] [paper preprint] [© IEEE]
Lu, Z., Carreira-Perpiñán, M. Á. and Sminchisescu, C. (2008):
People tracking with the Laplacian Eigenmaps Latent Variable Model.
Advances in Neural Information Processing Systems 20 (NIPS 2007), pp. 1705-1712.
[external link] [paper preprint] [poster] [slides] [animations]
Preview at The Learning Workshop 2007: [external link] [paper preprint] [poster]
Qin, C. and Carreira-Perpiñán, M. Á. (2007):
An empirical investigation of the nonuniqueness in the acoustic-to-articulatory mapping.
Interspeech 2007, pp. 74-77.
Best student paper award.
[external link] [paper preprint] [slides]
Qin, C. and Carreira-Perpiñán, M. Á. (2007):
A comparison of acoustic features for articulatory inversion.
Interspeech 2007, pp. 2469-2472.
[external link] [paper preprint] [slides]
Kazmierczak, S. C., Leen, T. K., Erdogmus, D. and Carreira-Perpiñán, M. Á. (2007):
Reduction of multi-dimensional laboratory data to a two-dimensional plot: a novel technique for the identification of laboratory error.
Clinical Chemistry and Laboratory Medicine 45(6):749-752.
[external link] [paper preprint]
Myronenko, A., Song, X. and Carreira-Perpiñán, M. Á. (2007):
Free-form nonrigid image registration using generalized elastic nets.
IEEE Conf. Computer Vision and Pattern Recognition (CVPR 2007).
[external link] [paper preprint] [poster] [© IEEE]
Carreira-Perpiñán, M. Á. and Lu, Z. (2007):
The Laplacian Eigenmaps Latent Variable Model.
11th Int. Conf. Artificial Intelligence and Statistics (AISTATS 2007), pp. 59-66.
[external link] [paper preprint] [poster] [slides] [animations] [Matlab implementation (coming soon)]
Myronenko, A., Song, X. and Carreira-Perpiñán, M. Á. (2007):
Non-rigid point set registration: Coherent Point Drift.
Advances in Neural Information Processing Systems 19 (NIPS 2006), pp. 1009-1016.
[external link] [paper preprint] [poster] [Matlab implementation]
Carreira-Perpiñán, M. Á. (2007):
Gaussian mean shift is an EM algorithm.
IEEE Trans. on Pattern Analysis and Machine Intelligence 29(5):767-776.
[external link] [paper preprint] [© IEEE]
We prove the following properties of the mean-shift algorithm: (1) Mean-shift is an expectation-maximisation (EM) algorithm for Gaussian kernels and a generalised EM algorithm for non-gaussian kernels. (2) Gaussian mean-shift converges linearly to a mode from almost any starting point; the rate of linear convergence approaches 0 (superlinear convergence) for very narrow or very wide kernels, but is often close to 1 (thus extremely slow) for intermediate widths, and exactly 1 (sublinear convergence) for widths at which modes merge. (3) The iterates approach the mode along the local principal component of the data points from the inside of the convex hull of the data points. (4) The convergence domains are nonconvex and can be disconnected and show fractal behaviour.
Carreira-Perpiñán, M. Á. (2006):
Fast nonparametric clustering with Gaussian blurring mean-shift.
23rd Int. Conf. Machine Learning (ICML 2006), pp. 153-160.
[external link] [paper preprint] [slides] [poster] [animations] [Java applet] [Matlab implementation]
We give a stopping criterion and an acceleration for the Gaussian blurring mean-shift algorithm, prove it has cubic convergence rate with Gaussian clusters, connect it with spectral clustering, and show it achieves image segmentations as good as those of Gaussian mean-shift but much faster.
Carreira-Perpiñán, M. Á. (2006):
Acceleration strategies for Gaussian mean-shift image segmentation.
IEEE Conf. Computer Vision and Pattern Recognition (CVPR 2006), pp. 1160-1167.
[external link] [paper preprint] [poster] [Java applet] [Matlab implementation (coming soon)] [© IEEE]
We attain speedups of one to two orders of magnitude over exact Gaussian mean-shift while achieving essentially the same segmentation, by using techniques based on spatial discretisation, spatial neighbourhoods, sparse EM and EM-Newton algorithms.
Myronenko, A., Song, X. and Carreira-Perpiñán, M. Á. (2006):
Non-parametric image registration using generalized elastic nets.
9th MICCAI Conference, Int. Workshop on Mathematical Foundations of Computational Anatomy (MFCA 2006), pp. 156-163.
[external link] [paper preprint]
Erdogmus, D., Carreira-Perpiñán, M. Á. and Özertem, U. (2006):
Kernel density estimation, affinity-based clustering, and typical cuts.
IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP'06), vol. 5 pp. 569-572.
[external link] [paper preprint] [© IEEE]
Carreira-Perpiñán, M. Á., Dayan, P. and Goodhill, G. J. (2005):
Differential priors for elastic nets.
6th Int. Conf. Intelligent Data Engineering and Automated Learning (IDEAL'05), pp. 335-342, Lecture Notes in Computer Science vol. 3578, Springer-Verlag.
[external link] [paper preprint] [Matlab implementation] [supplementary information] [© Springer-Verlag]
Carreira-Perpiñán, M. Á. and Hinton, G. E. (2005):
On contrastive divergence learning.
10th Int. Workshop on Artificial Intelligence and Statistics (AISTATS 2005), pp. 59-66, 2005.
[external link] [paper preprint] [poster]
Contrastive divergence (CD) is a fast, low-variance Markov chain Monte Carlo method for maximum likelihood estimation of random fields. We show that CD is typically slightly biased and give an unbiased alternative algorithm.
Carreira-Perpiñán, M. Á. and Zemel, R. S. (2005):
Proximity graphs for clustering and manifold learning.
Advances in Neural Information Processing Systems 17 (NIPS 2004), pp. 225-232.
[external link] [paper preprint] [slides] [poster]
We propose new types of proximity (neighbourhood) graphs, based on ensembles of minimum spanning trees, for use with (spectral) clustering and manifold learning.
Carreira-Perpiñán, M. Á., Lister, R. J., and Goodhill, G. J. (2005):
A computational model for the development of multiple maps in primary visual cortex.
Cerebral Cortex 15(8):1222-1233.
[external link] [paper preprint] [Matlab implementation] [supplementary information]
We model the combined development of 5 maps of primary visual cortex (retinotopy, ocular dominance, orientation, direction and spatial frequency) using the elastic net model, as well as the effects of monocular deprivation and single-orientation rearing. We also predict that the stripe width of all maps (orientation, direction, spatial frequency) increases slightly under monocular deprivation. This prediction has been confirmed by Farley et al., J. Neurosci. 2007.
Carreira-Perpiñán, M. Á. and Goodhill, G. J. (2004):
Influence of lateral connections on the structure of cortical maps.
J. Neurophysiology 92(5):2947-2959.
[external link] [paper preprint] [Matlab implementation] [supplementary information]
Using a generalised elastic net model of cortical maps, we show that the number of excitatory and inhibitory oscillations of a Mexican-hat cortical interaction function has a remarkable effect on the geometric relations between the maps of ocular dominance and orientation. We predict that, in biological maps, this function oscillates only once (central excitation, surround inhibition).
He, X., Zemel, R. S., and Carreira-Perpiñán, M. Á. (2004):
Multiscale conditional random fields for image labeling.
IEEE Conf. Computer Vision and Pattern Recognition (CVPR 2004), pp. 695-702, Washington, DC, 27 June - 2 July 2004.
[external link] [paper preprint] [Corel and Sowerby datasets (gzipped Matlab format)] [© IEEE]
Carreira-Perpiñán, M. Á.:
Reconstruction of sequential data with density models.
Unpublished manuscript, Jan. 27, 2004, arXiv:1109.3248.
[external link] [paper preprint]
Carreira-Perpiñán, M. Á. and Goodhill, G. J.:
Generalised elastic nets.
Unpublished manuscript, Aug. 14, 2003, arXiv:1108.2840 [q-bio.NC].
[external link] [paper preprint] [Matlab implementation] [supplementary information]
Carreira-Perpiñán, M. Á. and Williams, C. K. I. (2003):
An isotropic Gaussian mixture can have more modes than components.
Technical report EDI-INF-RR-0185, School of Informatics, University of Edinburgh, UK.
[external link] [paper] [supplementary information]
Carreira-Perpiñán, M. Á. and Williams, C. K. I. (2003):
On the number of modes of a Gaussian mixture.
Scale-Space Methods in Computer Vision, pp. 625-640, Lecture Notes in Computer Science vol. 2695, Springer-Verlag.
[external link] [paper preprint] [© Springer-Verlag] [extended technical report version] [supplementary information]
Carreira-Perpiñán, M. Á. and Williams, C. K. I. (2003):
On the number of modes of a Gaussian mixture.
Technical report EDI-INF-RR-0159, School of Informatics, University of Edinburgh, UK.
[external link] [paper] [supplementary information]
There is a typo in the equation just before section 3.2: in the expression β = ..., the exponent of s should be D+2 rather than 2. Thanks to Jan Magnus for pointing it out.
Carreira-Perpiñán, M. Á. and Goodhill, G. J. (2002):
Are visual cortex maps optimized for coverage?.
Neural Computation 14(7):1545-1560.
[external link] [paper preprint]
Carreira-Perpiñán, M. Á. and Goodhill, G. J. (2002):
Development of columnar structures in primary visual cortex.
Invited chapter in Computational Neuroanatomy: Principles and Methods (G. A. Ascoli, ed.), Humana Press, chapter 15, pp. 337-357.
[external link] [paper preprint]
This contains a review of data and models for visual cortical maps, with an emphasis on the elastic net.
Goodhill, G. J. and Carreira-Perpiñán, M. Á. (2002):
Cortical Columns.
Invited article in the Encyclopedia of Cognitive Science (L. Nadel, ed.), Macmillan, vol. 1, pp. 845-851.
[external link] [paper preprint]
This contains a review of columnar systems in the cortex, in particular in the visual cortex (maps of ocular dominance, orientation, etc.).
Carreira-Perpiñán, M. Á. and Goodhill, G. J. (2001):
The effect of variable elastic topologies on the structure of ocular dominance and orientation maps.
Society for Neuroscience abstracts, 27, 475.21.
[external link] [poster] [supplementary information]
Carreira-Perpiñán, M. Á. (2001):
Continuous latent variable models for dimensionality reduction and sequential data reconstruction.
PhD thesis, University of Sheffield, UK.
[external link] [abstract] [paper PDF] [paper PS] [list of all references (.tar.gz, BibTeX)]
The following chapters, available separately, contain tutorial material:
Carreira-Perpiñán, M. Á. (2000):
Mode-finding for mixtures of Gaussian distributions.
IEEE Trans. on Pattern Analysis and Machine Intelligence 22(11):1318-1323.
[external link] [paper preprint] [© IEEE] [extended technical report version] [Matlab implementation]
This gives algorithms for finding (nearly) all the maxima of a Gaussian mixture.
Carreira-Perpiñán, M. Á. (2000):
Reconstruction of sequential data with probabilistic models and continuity constraints.
Advances in Neural Information Processing Systems 12 (NIPS'99), pp. 414-420.
[external link] [paper preprint] [slides]
This gives a method for reconstructing a sequence of data vectors where some components at some times are missing, with applications to inverse problems in speech (articulatory inversion) and robotics (inverse kinematics).
Carreira-Perpiñán, M. Á. and Renals, S. (1999):
A latent variable modelling approach to the acoustic-to-articulatory mapping problem.
14th International Congress of Phonetic Sciences (ICPhS'99), pp. 2013-2016, San Francisco, USA, 1-7 August 1999.
[external link] [paper preprint] [slides]
Carreira-Perpiñán, M. Á. (1999):
One-to-many mappings, continuity constraints and latent variable models.
1999 IEE Colloquium on Applied Statistical Pattern Recognition, Birmingham, UK.
[external link] [paper preprint] [slides]
Carreira-Perpiñán, M. Á. and Renals, S. (2000):
Practical identifiability of finite mixtures of multivariate Bernoulli distributions.
Neural Computation 12(1):141-152.
[external link] [paper preprint] [Matlab implementation]
Mixtures of multivariate Bernoulli distributions are known to be nonidentifiable. We give empirical support to their "practical identifiability" and conjecture that only a small portion of the parameter space may be nonidentifiable. We also give practical advice in estimating the best number of components with an EM algorithm. This conjecture has been recently proven (Allman et al., Ann. Statist. 2009, Elmore et al., Ann. Inst. Fourier 2005): the region of nonidentifiability in parameter space has measure zero for sufficiently many variables.
Carreira-Perpiñán, M. Á. (1999):
Mode-finding for mixtures of Gaussian distributions (revised August 4, 2000).
Technical report CS-99-03, Dept. of Computer Science, University of Sheffield, UK.
[external link] [paper] [supplementary information]
Carreira-Perpiñán, M. Á. and Renals, S. (1998):
Dimensionality reduction of electropalatographic data using latent variable models.
Speech Communication 26(4):259-282.
[external link] [paper preprint] [supplementary information]
Carreira-Perpiñán, M. Á. and Renals, S. (1998):
Experimental evaluation of latent variable models for dimensionality reduction.
1998 IEEE Signal Processing Society Workshop on Neural Networks for Signal Processing (NNSP98), pp. 165-173, Cambridge, UK.
[external link] [paper preprint] [© IEEE] [slides]
Carreira-Perpiñán, M. Á. (1997):
Density networks for dimension reduction of continuous data: Analytical solutions.
Technical report CS-97-09, Dept. of Computer Science, University of Sheffield, UK.
[external link] [paper]
Carreira-Perpiñán, M. Á. (1996):
A review of dimension reduction techniques.
Technical report CS-96-09, Dept. of Computer Science, University of Sheffield, UK.
[external link] [paper]
Note: this document is out of date. A much more extensive review is provided in chapters 2 and 4 of my PhD thesis.
Carreira-Perpiñán, M. Á. (1995):
Compression neural networks and feature extraction: Application to human recognition from ear images (in Spanish).
MSc thesis, Technical University of Madrid, Spain.
[abstract] [paper] [slides] [database of ear images]
This is probably the first work that introduces the idea of ear biometrics for automatic personal identification.
Carreira-Perpiñán, M. Á. (1994):
The modelling of the thermal subsystem in spacecraft real-time simulators.
3rd Workshop on Simulators for European Space Programmes, pp. 69-78, ESA/ESTEC, Noordwijk, The Netherlands.
[paper] [slides]
Carreira-Perpiñán, M. Á. (1994):
ESA Thermal Analysis Program (ESATAN): An evaluation.
European Space Agency Internal Report DOPS-SST-TN-0215-SIM, Darmstadt, Germany.
[paper]
Carreira-Perpiñán, M. Á. (2016): CSE176 Introduction to Machine Learning: Lecture notes. University of California, Merced, 2015-2016.
Carreira-Perpiñán, M. Á. (2016): EECS260 Optimization: Lecture notes. University of California, Merced, 2008-2016.
Carreira-Perpiñán, M. Á. (2006): EE 589/689 Foundations of computer vision: Lecture notes. OGI/OHSU, Fall quarter 2006.
Gabidolla, Magzhan (2025): The role of alternating optimization in learning decision tree ensembles. PhD thesis, University of California, Merced.
[external link] [paper] [slides]
Zharmagambetov, Arman (2022): Learning tree-based models with manifold regularization: alternating optimization algorithms. PhD thesis, University of California, Merced.
[external link] [paper] [slides]
Hada, Suryabhan Singh (2022): Some approaches to interpret deep neural networks. PhD thesis, University of California, Merced.
[external link] [paper] [slides]
Idelbayev, Yerlan (2021): Low-rank compression of neural networks: LC algorithms and open-source implementation. PhD thesis, University of California, Merced.
[external link] [paper] [slides]
Vladymyrov, Max (2014): Large-scale methods for nonlinear manifold learning. PhD thesis, University of California, Merced.
[external link] [paper] [slides]
Wang, Weiran (2013): Mean-shift algorithms for manifold denoising, matrix completion and clustering. PhD thesis, University of California, Merced.
[external link] [paper] [slides]
Kamthe, Ankur (2012): Data-driven modeling of phenomena in wireless sensor networks. PhD thesis, University of California, Merced.
[external link] [paper] [slides]
Qin, Chao (2011): Data-driven approaches to articulatory speech processing. PhD thesis, University of California, Merced.
[external link] [paper] [slides]
![]() Can't get a paper? Questions? Just email me.
Can't get a paper? Questions? Just email me.
Useful downloads: ![]() Adobe Acrobat
Adobe Acrobat ![]() Ghostscript
Ghostscript ![]() QuickTime
QuickTime ![]() Windows Media Player
Windows Media Player ![]() Real Player
Real Player
{kind=link}