Note: this page contains a number of colour images. To view it best, set the width of your browser window to at least 820 pixels, its height to at least 700, and as many colours as possible. The following horizontal rule is 820 pixels long.
Also, coloured fonts are used to interpret the graphs, which may clash with some colour customisation you may have.
Electropalatograms (EPGs) are typically 62-component binary vectors indicating the presence or absence of linguopalatal contact in particular moments of an utterance. Abundant data is available from the ACCOR II database, produced with the EPG system of the University of Reading. Traditional EPGs are plane views of the articulatory process; enhanced EPG systems providing 3D data are currently under development.
Dimensionality reduction of EPG data can be useful in several ways:
Some ad hoc reduction strategies have been proposed for EPGs (Hardcastle et al. 1989, 1991), but little work using adaptive techniques has been done. We have used latent variable models and finite mixtures to fit maximum likelihood models to a subset of the ACCOR database. We show that these unsupervised learning methods can extract important structure from the EPG data and perform well in varying speech conditions (e.g. different speakers or different speech styles). In particular, nonlinear methods present a clear advantage over linear ones. You can find more about this research in the following papers:
The subset of the ACCOR database that we used included EPG frames sampled from several different utterances by 6 English native speakers (FG, HD, KM, PD, RK, SN). This is how some typical EPG frames look like (below is the corresponding phoneme):
![[Image (gif 6K): Typical EPG prototypes]](epg/gif/epg_prototypes.gif)
Each 62-dimensional vector is represented in the customary way as a two-dimensional 8x8 image (where the top corners are unused): components 1-6 in the first row (alveoli), components 7-14 in the second,..., components 55-62 in the eighth row (velum). Each vector component is scaled to [-1,1] and plotted as follows:
We partitioned the data set into 6 subsets, each of them corresponding to a different speaker (FG, HD, KM, PD, RK, SN). Each subset was itself split into a training (75% of the frames) and a test set (25%). For each speaker and using the training set, we found maximum likelihood estimates for the following models:
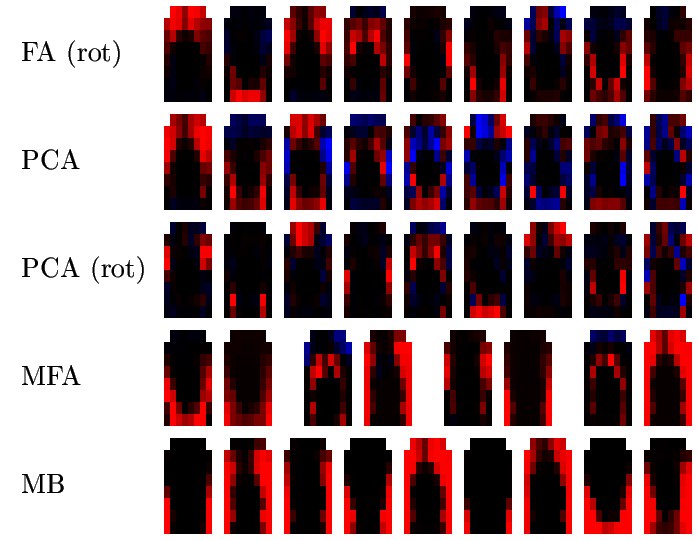
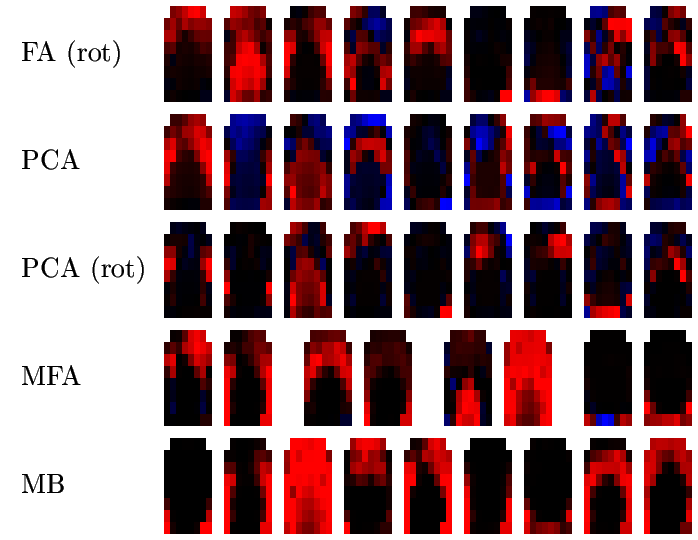
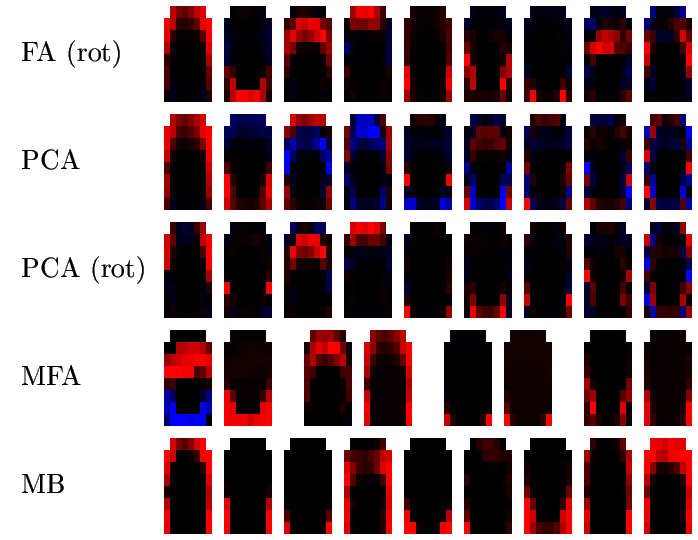
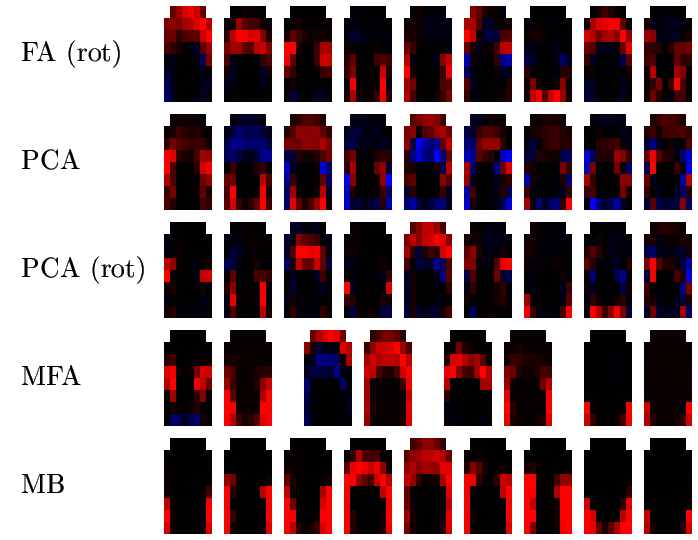
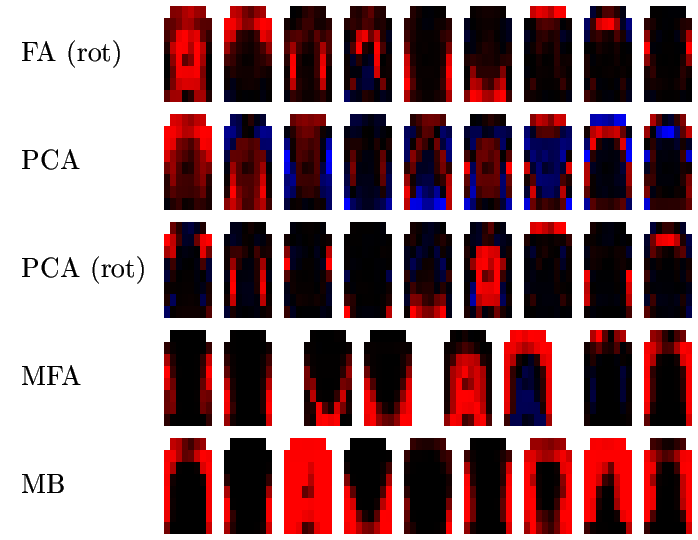
The following picture shows, for speaker RK, the factors or prototypes extracted by FA, PCA, MFA and MB as follows:
![[Image (60K): Prototypes for speaker RK]](epg/gif/prototypes_rk.gif)
Similar pictures are available for the rest of the speakers: FG, HD, KM, PD, RK, SN.
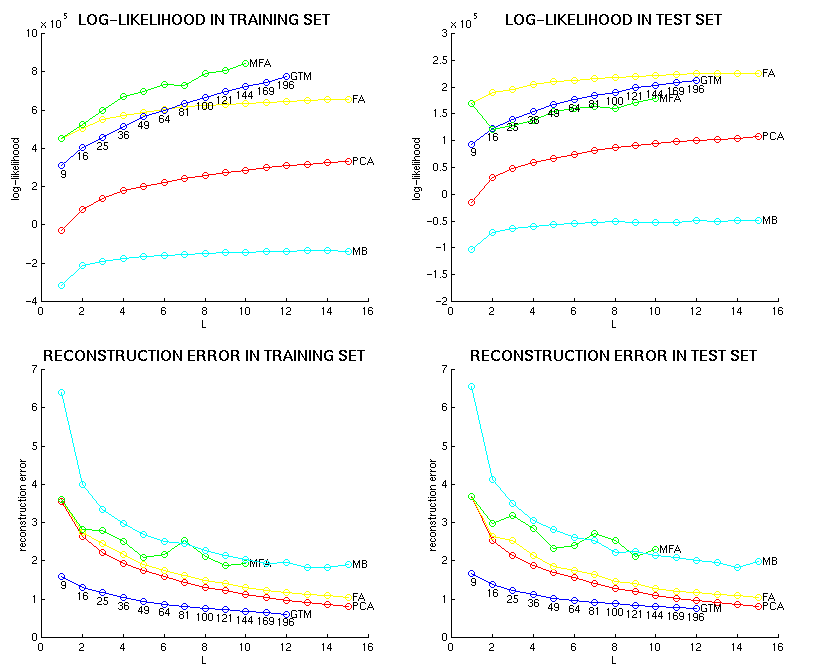
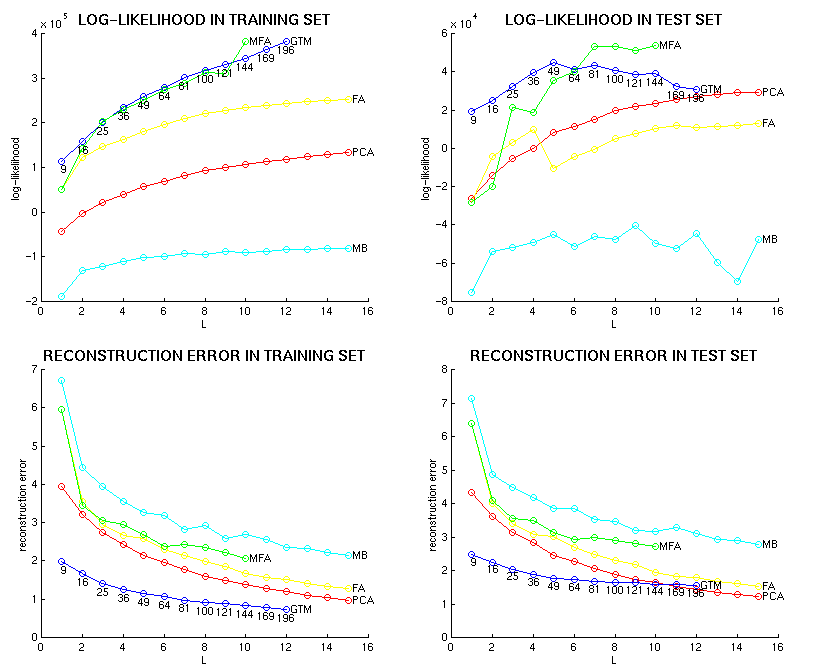
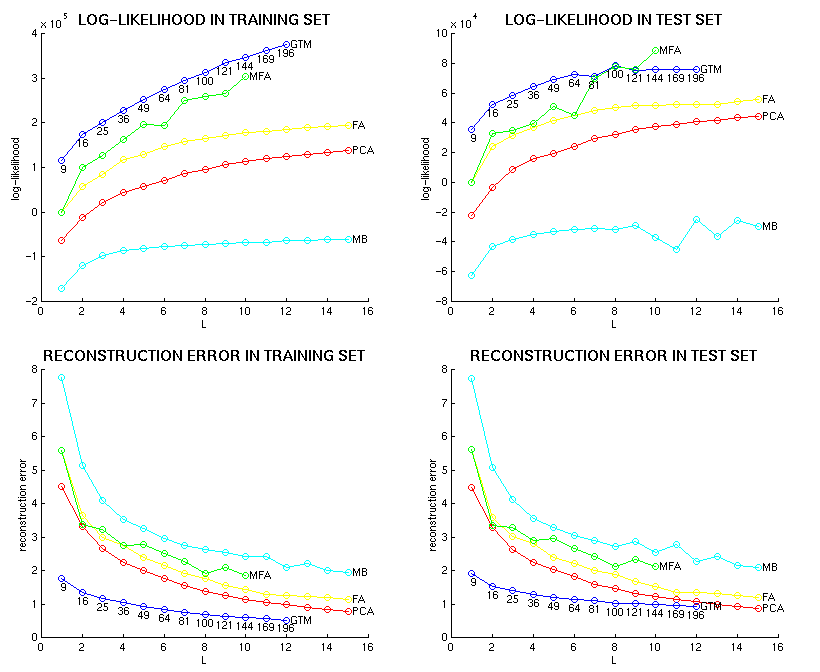
The comparative performance of factor analysis (FA), principal component analysis (PCA), the two-dimensional generative topographic mapping (GTM), the mixture of first-order factor analysers (MFA) and the mixture of multivariate Bernoulli distributions (MB) is shown in the following graphs for speaker RK in terms of log-likelihood and squared reconstruction error in the training set and the test set:
![[Image (19K): Log-likelihood and squared reconstruction error for speaker RK]](epg/gif/llh_rec-error_rk.gif)
Note that the X axis refers to the order of the factor analysis or principal components analysis, the number of mixture components in the case of mixture models and the square root of the number of basis functions in the case of the two-dimensional GTM.
Similar pictures are available for the rest of the speakers: FG, HD, KM, PD, RK, SN.
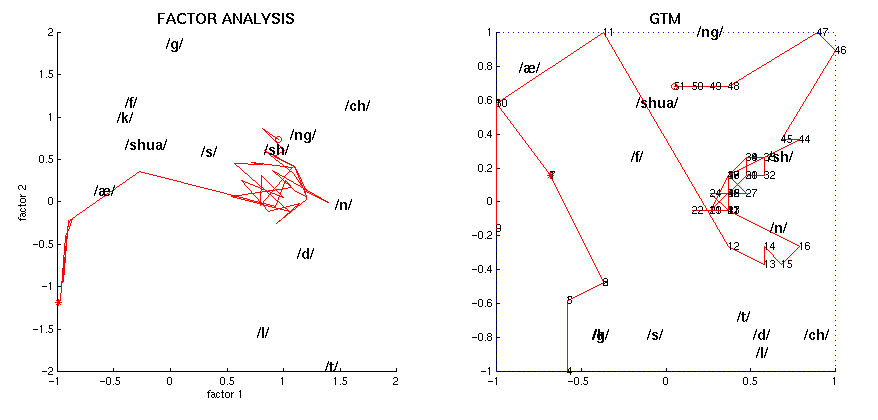
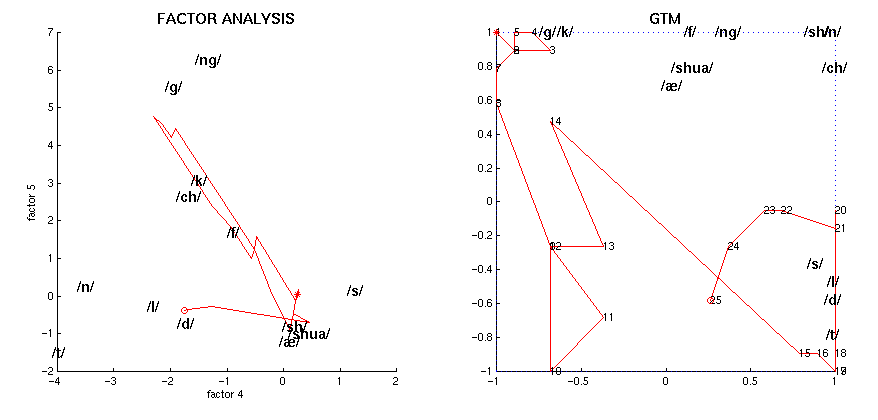
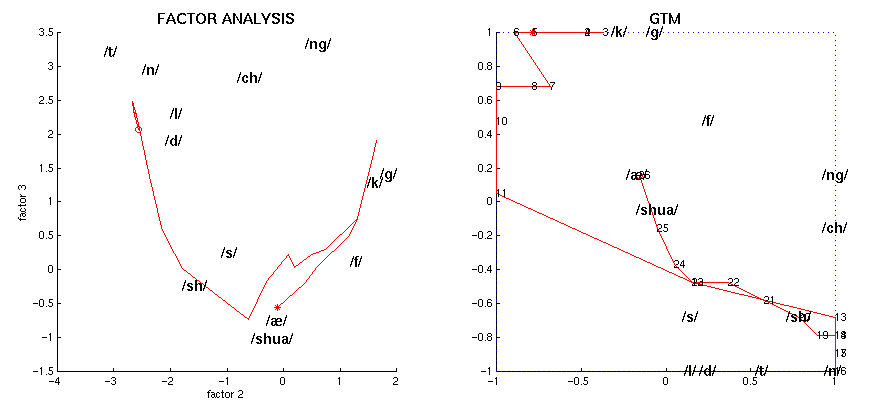
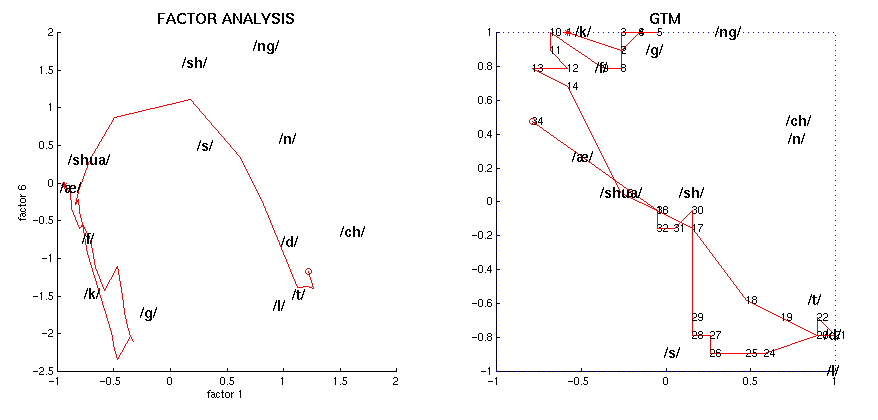
The following figure shows the projection onto a two-dimensional latent space of all the EPG frames from the highlighted fragment of the utterance "I prefer Kant to Hobbes for a good bedtime book", linking consecutive points by a line, for speaker RK. The phonemic transcription of the utterance is:
The left graph uses the latent space of factors 1 and 2, while the right one uses GTM (points are numbered correlatively). The start and end points are marked as * and o, respectively. The phonemes are those of the aforementioned figure.
![[Image (gif 9K): 2D plot for speaker RK]](epg/gif/2Dplot_rk.gif)
Similar pictures are available for the rest of the speakers: FG, HD, KM, PD, RK, SN.
I have put together some Matlab programs to find maximum likelihood estimates of some models and perform various other operations:
You can find Matlab software for other models elsewhere:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}