Generalized Linear Aggregate Distributed Engine (GLADE)
We have built GLADE as our scalable and highly-parallel data processing infrastructure starting in 2008. DataPath is the original shared-memory relational engine for multi-query processing that uses extensive multi-threading and code generation in order to process long analytical queries. GLADE adds distributed processing and support for complex aggregates with a well-defined API. This allows for applications to online aggregation (2013), gradient descent optimization for machine learning training (2013), array processing (2013), astronomical transient detection (2014), raw data processing (2014), quantile estimation (2015), multi-query optimization (2016), in-database linear algebra (2016), etc. In the following, we present the GLADE architecture.
GLADE is a scalable distributed framework for large scale data analytics. GLADE consists of a simple user-interface to define Generalized Linear Aggregates (GLA), the fundamental abstraction at the core of GLADE, and a distributed runtime environment that executes GLAs by using parallelism extensively.
GLAs are derived from User-Defined Aggregates (UDA), a relational database extension that allows the user to add specialized aggregates to be executed inside the query processor. GLAs extend the UDA interface with methods to Serialize/Deserialize the state of the aggregate required for distributed computation. As a significant departure from UDAs which can be invoked only through SQL, GLAs give the user direct access to the state of the aggregate, thus allowing for the computation of significantly more complex aggregate functions.
GLADE runtime is an execution engine optimized for the GLA computation. The runtime takes the user-defined GLA code, compiles it inside the engine, and executes it right near the data by taking advantage of parallelism both inside a single machine as well as across a cluster of computers. This results in maximum possible execution time performance and linear scaleup.
GLADE provides a framework for the execution of analytical tasks that are associative-decomposable using the iterator-based interface. It exposes the UDA interface consisting of four user-defined functions. The input consists of tuples extracted from a column-oriented relational store, while the output is the state of the computation. The execution model is a multi-level tree in which partial aggregation is executed at each level. The system is responsible for building and maintaining the tree and for moving data between nodes. Except these, the system executes only user code. The blend of column-oriented relations with a tree-based execution architecture allows GLADE to obtain remarkable performance for a variety of analytical tasks---billions of tuples are processed in seconds using only a dozen of commodity nodes.
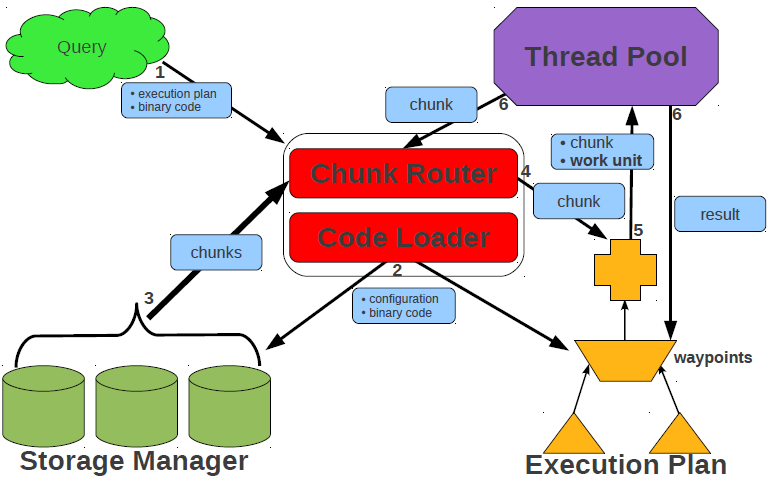
GLADE is derived from the relational execution engine DataPath, a highly efficient multi-query processing database system. The DataPath execution engine has at its core two components: waypoints and work units. A waypoint manages a particular type of computation, e.g., selection, join, etc. The code executed by each waypoint is configured at runtime based on the running queries. In DataPath, all the queries are compiled and loaded in the execution engine at runtime rather than being interpreted. This provides a significant performance improvement at the cost of some negligible compilation time. A waypoint is not executing any query processing job by itself. It only delegates a particular task to a work unit. A work unit is a thread from a thread pool (there are a fixed number of work units in the system) that can be configured to execute tasks. At a high level, the way the entire query execution process happens in DataPath is as follows:
-
When a new query arrives in the system, the code to be executed is first generated, then compiled and loaded into the execution engine. Essentially, the waypoints are configured with the code to execute for the new query.
-
Once the storage manager starts to produce chunks for the new query, they are routed to waypoints based on the query execution plan.
-
If there are available work units in the system, a chunk and the task selected by its current waypoint are sent to a work unit for execution.
-
When the work unit finishes a task, it is returned to the pool and the chunk is routed to the next waypoint.

GLADE consists of two types of entities: a coordinator and one or more executor processes. The coordinator is the interface between the user and the system. Since it does not manage any data except the catalog metadata, the coordinator does not execute any data processing task. These are the responsibility of the executors, typically one for each physical processing node. Each executor runs an instance of DataPath enhanced with a GLA metaoperator for the execution of arbitrary user code specified using the GLA interface.
Communication Manager is in charge of transmitting data across process boundaries, between the coordinator and the executors, and between individual executors. Different inter-process communication strategies are used in a centralized environment with the coordinator and the executor residing on the same physical node and for a distributed shared-nothing system. The communication manager at the coordinator is also responsible for maintaining the list of active executors. This is realized through a heartbeat mechanism in which the executors send alive messages at fixed time intervals.
Query Manager is responsible for admission, setup, and query processing coordination across executors and queries. This is a particularly important task since processing is asynchronous both with respect to executors as well as to queries.
Code Generator fills pre-defined M4 templates with macros specific to the actual processing requested by the user generating highly-efficient C++ code similar to direct hard-coding of the processing for the current data. The resulting C++ code is subsequently compiled together with the system code into a dynamic library. This mechanism allows for the execution of arbitrary user code inside the execution engine through direct invocation of the GLA interface methods.
Code Loader links the dynamic library to the core of the system allowing the execution engine and the GLA manager to directly invoke user-defined methods. While having the code generator at the coordinator is suitable for homogeneous systems, in the case of heterogeneous systems both the code generator and the code loader can reside at the executors.
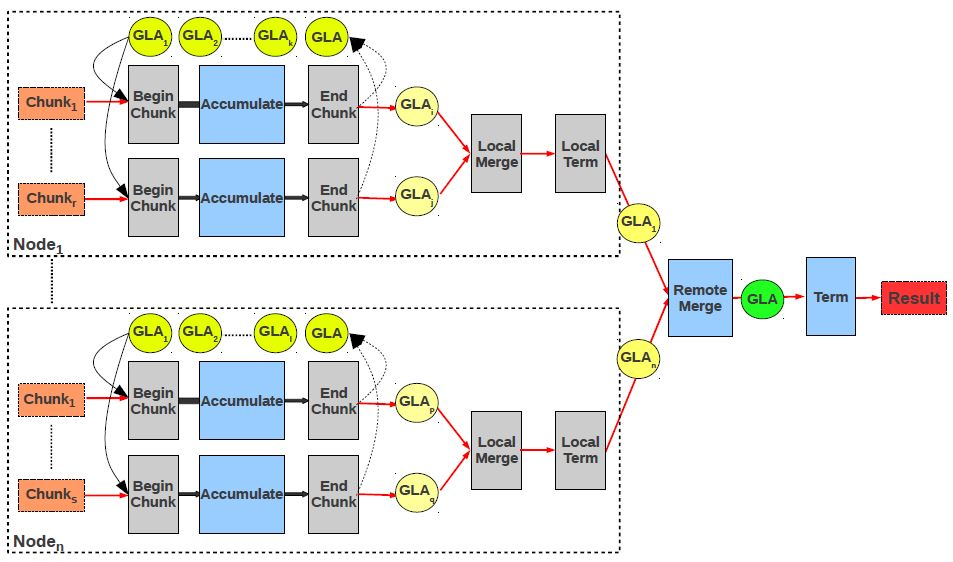
GLA Manager executes Merge at executors and Terminate at coordinator, respectively. These functions from the GLA interface are dynamically configured with the code to be executed at runtime based on the actual processing requested by the user. Notice that the GLA manager merges only GLAs from different executors, with the local GLAs being merged inside the execution engine.
Catalog maintains metadata on all the objects in the system such as table names and attribute names and their partitioning scheme. These data are used during code generation, query optimization, and execution scheduling. In addition to the global catalog, each executor has a local catalog with metadata on how its corresponding data partition is organized on disk.
Storage Manager is responsible for organizing data on disk, reading, and delivering the data to the execution engine for processing. The storage manager operates as an independent component that reads data asynchronously from disk and pushes it for processing. It is the storage manager rather than the execution engine in control of the processing through the speed at which data are read from disk. In order to support a highly-parallel execution engine consisting of multiple execution threads, the storage manager itself uses parallelism for simultaneously reading multiple data partitions.
When a job is received by the coordinator, the following steps are executed:
-
The coordinator generates the code to be executed at each waypoint in the DataPath execution plan. A single execution plan is used for all the workers.
-
The coordinator creates an aggregation tree connecting all the workers. The tree is used for in-network aggregation of the GLAs.
-
The execution plan, the code, and the aggregation tree information are broadcasted to all the workers.
-
Once the worker configures itself with the execution plan and loads the code, it starts to compute the GLA for its local data.
-
When a worker completes the computation of the local GLA, it first communicates this to the coordinator---the coordinator uses this information to monitor how the execution evolves. If the worker is a leaf, it sends the serialized GLA to its parent in the aggregation tree immediately.
-
A non-leaf node has one more step to execute. It needs to aggregate the local GLA with the GLAs of its children. For this, it first deserializes the external GLAs and then executes another round of Merge functions. In the end, it sends the combined GLA to the parent.
-
The worker at the root of the aggregation tree calls the function Terminate before sending the final GLA to the coordinator who passes it further to the client who sent the job.
For a more detailed description of GLADE and experimental results, check the following papers:
-
Automatic Identification and Classification of Palomar Transient Factory Astrophysical Objects in GLADE
by W. Zhao, F. Rusu, P. Nugent, and K. Wu
-
Implementing the Palomar Transient Factory Real-Time Detection Pipeline in GLADE: Results and Observations
by F. Rusu, P. Nugent, and K. Wu
-
GLADE: Big Data Analytics Made Easy
by Y. Cheng, C. Qin, and F. Rusu
-
GLADE: A Scalable Framework for Efficient Analytics
by F. Rusu and A. Dobra
UC Merced |
EECS |
Home
Last updated: Wednesday, December 13, 2017