SCANRAW
SCANRAW is a novel database meta-operator for in-situ processing over raw files that integrates data loading and external tables seamlessly, while preserving their advantages: optimal performance across a query workload and zero time-to-query. SCANRAW has a parallel superscalar pipeline architecture that overlaps data reading, conversion into the database representation, and query processing. SCANRAW integrates data partitioning, task parallelism and pipelining, and vectorized instructions for raw file data processing. An adaptive scheduling strategy for dynamically assigning worker threads to extraction tasks is used to optimize resource utilization in the system and minimize query execution time while maximizing the amount of data loaded into the database. A merge read mechanism is employed for reading data from multiple sources. Merge read groups multiple requests corresponding to the same data source and schedules them together. SCANRAW introduces speculative loading as a gradual data loading mechanism that dynamically and adaptively takes advantage of the disk idle intervals arising during data conversion and query processing and multistep loading for storing raw data into the database, without immediate conversion to the internal format. Since data are converted into binary lazily, a significant improvement is achieved in CPU-bound tasks by eliminating parsing of unnecessary columns. Several instances of SCANRAW are implemented, e.g., SCANRAW-CSV, SCANRAW-SAM, SCANRAW-BAM, SCANRAW-FITS, SCANRAW-JSON, SCANRAW-HDF5, for a variety of data formats.
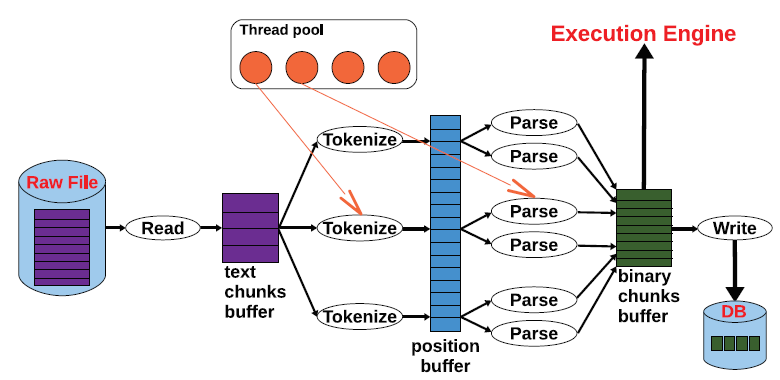
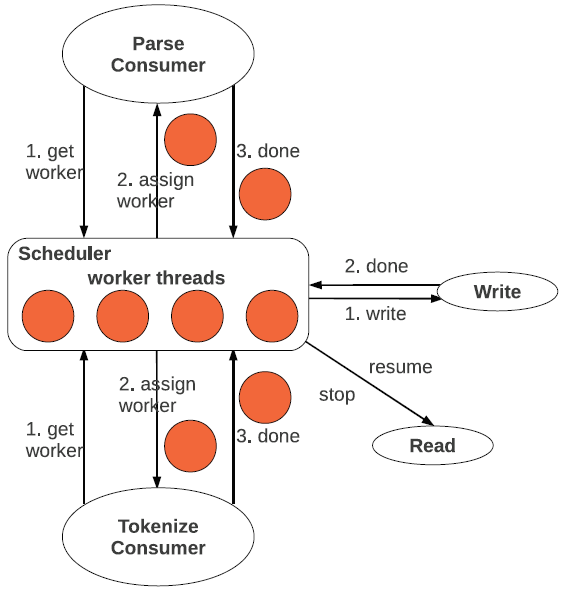
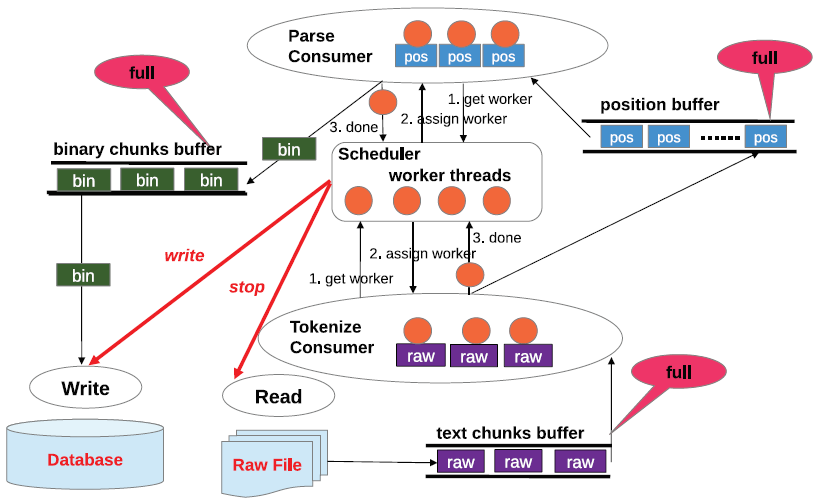
The superscalar pipeline architecture of SCANRAW contains multiple TOKENIZE and PARSE stages. They operate on different portions of the data in parallel, that is, data partitioning parallelism. MAP is not an independent stage anymore, it is contained in PARSE. The scheduling of these stages is managed by a scheduler controlling a pool of worker threads. The scheduler assigns worker threads to stages dynamically at runtime. READ and WRITE are also controlled by the scheduler thread in order to coordinate disk access and avoid interference. The scheduling policy for WRITE dictates the SCANRAW behavior. If the scheduler never invokes WRITE, SCANRAW becomes a parallel external table operator. If the scheduler invokes WRITE for every chunk, SCANRAW converts into a parallel Extract-Transform-Load (ETL) operator. One potential problem with the superscalar pipeline architecture is that chunks can be passed to the execution engine in a different order than the raw file. This is possible because of the multiple parallel paths a chunk can take. While not a problem in the relational data model, this can be an issue if strict ordering is required. SCANRAW can handle this scenario using a similar approach to CPUs - reordering at the binary chunks buffer. SCANRAW has a dynamic pipeline structure that configures itself according to the input data. Whenever data become available in one of the buffers, a thread is extracted from the thread pool and is assigned the corresponding operation and the data for execution. The maximum degree of parallelism that can be achieved is equal to the number of threads in the pool. The number of threads in the pool is configured dynamically at runtime for each SCANRAW instance. Data that cannot find an available thread are stored in the corresponding buffer until a thread becomes available. This effect is back-propagated through the pipeline structure downto READ which stops producing data when no empty slots are available in the text chunk buffer. The binary chunks cache plays a central role in configuring the SCANRAW functionality. By default, all the converted binary chunks are cached, that is, they are not eliminated from the cache once passed into the execution engine or WRITE. If all the chunks in the raw file can be cached, SCANRAW simply delivers the chunks to the execution engine and the database becomes an in-memory database. SCANRAW starts to prefetch chunks as soon as the query is compiled and caches them in the binary chunks buffer. The goal is to guarantee that the execution engine is fed continuously with data and the delay introduced by the I/O is minimized. Prefetching stops only when the buffer is full with chunks not already processed by the execution engine. SCANRAW extracts valuable metadata while converting raw chunks into binary. These metadata are stored in the catalog to be used for processing subsequent queries. The extracted metadata include the position in the raw file where each chunk begins and for every attribute the minimum and maximum value in the chunk. SCANRAW implements two scheduling strategies for the dynamic pipeline structure. In best-effort scheduling, the scheduler assigns a worker thread to a task based on the first-come first-serve (FCFS) mechanism. Best-effort scheduling guarantees that all the available threads are working in parallel as much as possible, particularly for computation-intensive tasks, since the system assigns threads without delay. Adaptive scheduling assigns worker threads according to the runtime system state which includes the available resource status and statistics on current and past workloads. When the scheduler has to decide to which stage to assign the next available worker thread, it calculates a priority value for all the stages, and the candidate with the highest value receives the thread. Moreover, the scheduler aims to fill the pipeline within the available resource restrictions. Adaptive scheduling not only guarantees balanced system utilization but can also adapt automatically to workload imbalance.
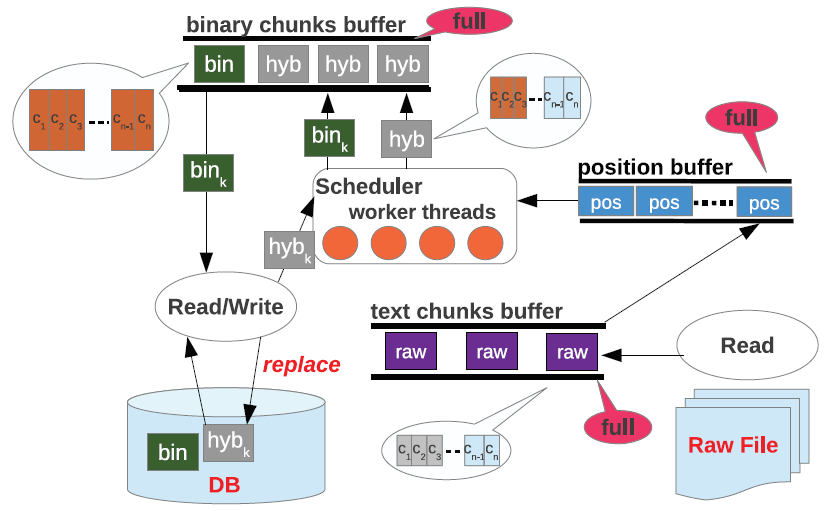
The main idea in speculative loading is to find those time intervals during raw file query processing when there is no disk reading going on and use them for database writing. The intuition is that query processing speed is not affected since the execution is CPU-bound and the disk is idle. Notice though that a highly-parallel architecture consisting of asynchronous threads capable of detecting free I/O bandwidth and overlap processing with disk operations is required in order to implement speculative loading. SCANRAW decides adaptively at runtime what data to load, how much, and when, while maintaining the best-possible query execution performance. These decisions are taken dynamically by the scheduler in charge of coordinating disk access between READ and WRITE. Since the scheduler monitors the utilization of the buffers and assigns worker threads for task execution, it can identify when READ is blocked. At that time, the scheduler signals WRITE to load chunks in the database. While the maximum number of chunks to be loaded is determined by the scheduler based on the pipeline utilization, the actual chunks are strictly determined by WRITE based on the catalog metadata. It is important for the scheduler not to allow reading to start before writing finishes in order to avoid disk interference. This is realized with the resume control message whenever worker threads become available and WRITE returns.
This project is partially supported by a DOE Early Career Award. The results are published in the following papers:
-
Vertical Partitioning for Query Processing over Raw Data
by W. Zhao, Y. Cheng and F. Rusu
-
Workload-Driven Vertical Partitioning for Effective Query Processing over Raw Data
by W. Zhao, Y. Cheng and F. Rusu
-
SCANRAW: A Database Meta-Operator for Parallel In-Situ Processing and Loading
by Y. Cheng and F. Rusu
-
Parallel In-Situ Data Processing with Speculative Loading
by Y. Cheng and F. Rusu
UC Merced |
EECS |
Home |
In-Situ Data Processing
Last updated: Thursday, December 14, 2017