In-Situ Data Processing
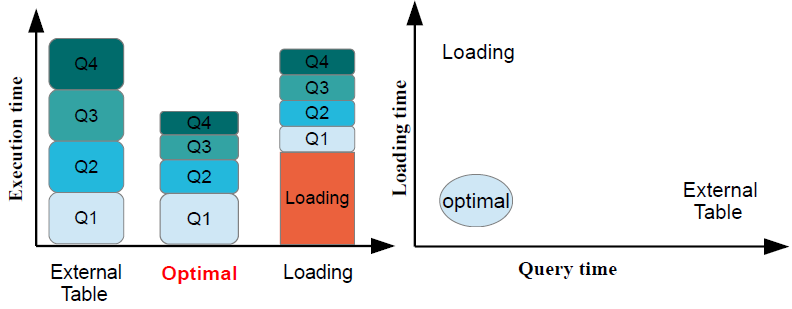
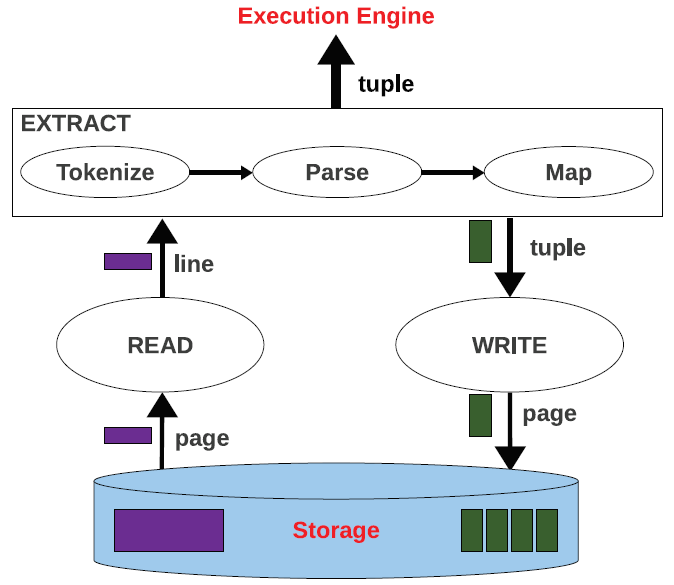
In the era of data deluge, massive amounts of data are generated at an unprecedented scale by applications ranging from social networks to scientific experiments and personalized medicine. The vast majority of these read-only data are stored as application-specific files containing hundreds of millions of records. Due to the upfront loading cost and the proprietary file format, databases are rarely considered as a storage solution, even though they provide enhanced querying functionality and performance. Instead, the standard practice is to write dedicated applications encapsulating the query logic on top of generic file access libraries that provide instant access to data through a well-defined API. While a series of applications for a limited set of parametrized queries are provided with the library, new queries typically require the implementation of a completely new application, even when there is significant logic that can be reused. Relational databases avoid this problem altogether by implementing a declarative querying mechanism based on SQL. This requires data representation independence, though, achieved through loading and storing data in a proprietary format. External tables combine the advantages of file access libraries and the declarative query execution mechanism provided by SQL: data can be queried in the original format using SQL. Thus, there is no loading penalty and querying does not require the implementation of a complete application. When compared to standard database query optimization and processing, external tables use linear scan as the single file access strategy since no storage optimizations are possible, as data are external to the database. Every time data are accessed, they have to be converted from the raw format into the internal database representation. As a result, query performance is both constant and poor. Databases, on the other hand, trade query performance for a lengthy loading process. Although time consuming, data loading is a one-time process, amortized over the execution of a large number of queries. The more queries are executed, the more likely that the database outperforms external tables in response time.
Our work in this area has begun with the SCANRAW (2014) super-scalar meta-operator for parallel in-situ processing with speculative loading. Then, we have explored vertical partitioning of raw files (2015) where some of the partitions are loaded into the database; the integration of in-situ processing and online aggregation in OLA-RAW (2016); and code generation techniques for raw data processing (2017). Lastly, we have proposed distributed caching algorithms for raw arrays (2018).
UC Merced |
EECS |
Home
Last updated: Monday, July 22, 2019