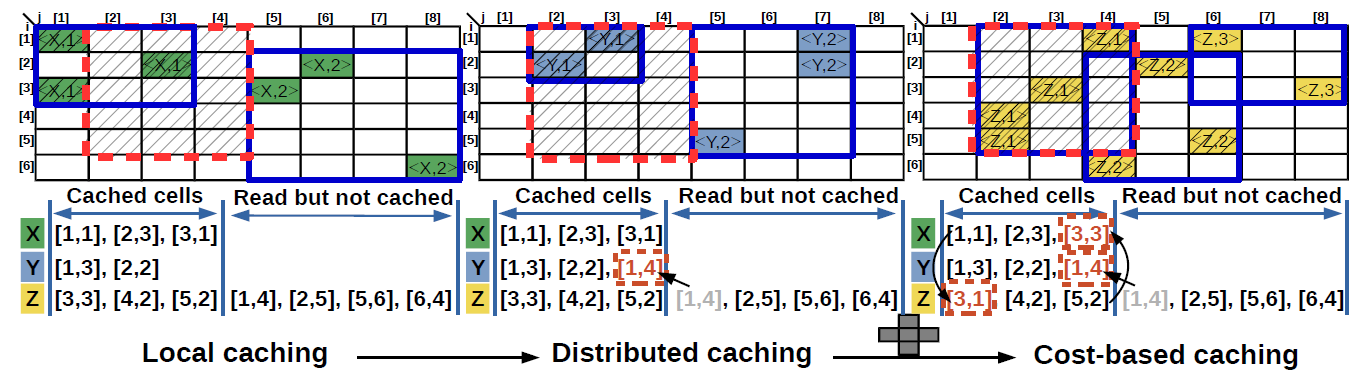
We design a distributed caching framework that computes an effective caching plan in two stages. First, the plan identifies the cells to be cached locally from each of the input files by continuously refining an evolving R-tree index. Each query range generates a finer granularity bounding box that allows advanced pruning of the raw files that require inspection. This guarantees that - after a sufficiently large number of queries - only relevant files are scanned. In the second stage, an optimal assignment of cells to nodes that collocates dependent cells in order to minimize the overall data transfer is determined. We model cache eviction and placement as cost-based heuristics that generate an effective cache eviction plan and reorganize the cached data based on a window of historical queries. We design efficient algorithms for each of these stages. In the long run, the reorganization improves cache data co-locality by grouping relevant portions of the array and by balancing the computation across nodes.
The array distributed caching framework works as follows. First, the execution engine sends the subarray and the shape in the array similarity join query to the cache coordinator which has to determine the chunk pairs that have to be joined. While these can be immediately inferred from the catalog for loaded data, there is no chunking - or the chunking is not known - for raw data. The naive solution to handle this problem is to treat each file as a chunk and perform the similarity join between pairs of files. Since a file covers a much larger range and is not organized based on cell locality, this solution accesses many unnecessary cells and uses the cache budget inefficiently. Our approach is to build in-memory chunks incrementally based on the query, i.e., workload-driven chunking. These chunks are built by the cache nodes by accessing the files that overlap with the query - the only data the cache coordinator forwards to the nodes. Instead of extracting chunks only for the queried data, the cache nodes create higher granularity chunks for the entire file. Since chunk building requires raw file access - which is expensive - caching is very important for efficient processing. In the best case, the entire file can be cached. Otherwise, a cache replacement policy is required to determine the chunks to keep in memory. Once evicted from memory, the chunks are lost since they have to be recreated from the raw data. While it is possible to materialize the evicted chunks in some representation, e.g., R-tree, this replicates data and adds another dimension to the problem. Instead of allowing each node to execute a local cache replacement algorithm, e.g., LRU, we develop a global cost-based caching mechanism executed at the coordinator. This algorithm takes the metadata of all the created chunks across nodes and determines the chunks to be evicted from the cache in a unified way. This may incur chunk transfer across nodes. Since query evaluation also requires chunk transfer and replication, we go one step further and combine query processing with cache replacement. Specifically, cache replacement piggybacks on the query execution plan and eliminates extra chunk transfer. Moreover, the location of a cached chunk is computed by considering the relationship with other chunks in the historical query workload. This is implemented as follows. Upon receiving the chunk metadata from the nodes, the coordinator query optimizer computes the optimal query execution plan which specifies what node joins each of the chunk pairs. This is passed to the cache coordinator which computes the cache replacement plan by combining the execution plan with chunk usage statistics and chunk co-locality information. The cache replacement plan informs every node on what chunk replica to cache and which chunks to evict. Finally, these two plans are forwarded to the nodes for execution. The engine executes the query and the cache executes the replacement plan, in this sequence.
UC Merced | EECS | Home | Array Databases