OLA-RAW
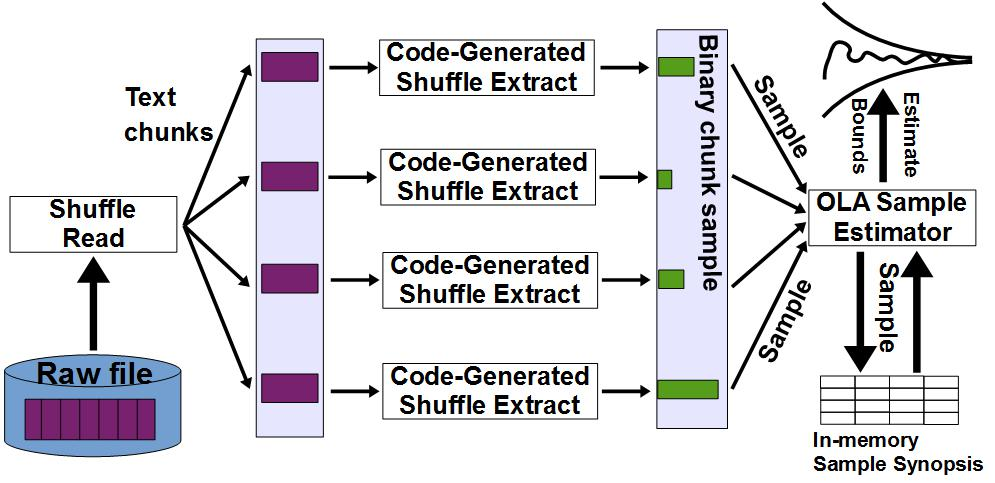
OLA-RAW seamlessly integrates online aggregation (OLA) into raw data processing (RAW). Similar to RAW, OLA-RAW distributes data loading across the query workload. The same idea is extended to shuffling. Instead of randomly permuting all the data before performing online aggregation, OLA-RAW partitions shuffling across the queries in the workload. Moreover, loading and shuffling are combined incrementally such that loaded data do not require further shuffling. Essentially, OLA-RAW provides a resource-aware parallel mechanism to adaptively extract and incrementally maintain samples from raw data. The end goal is to reduce the high upfront cost of loading (DBMS) and shuffling (OLA), and to minimize the amount of data accessed by RAW. OLA-RAW sampling is query-driven and performed exclusively in-situ during query execution, without data reorganization. We provide a parallel chunk-level sampling mechanism that avoids the inherent inspection paradox. We introduce a novel parallel bi-level sampling scheme that supports continuous estimation -- not only at chunk boundaries -- during the online aggregation process. We devise a resource-aware policy to determine the optimal chunk sample size for the proposed bi-level sampling scheme. In order to avoid the expensive conversion cost, OLA-RAW builds and maintains incrementally a memory-resident bi-level sample synopsis following a variance-driven strategy.
Holistic Sampling
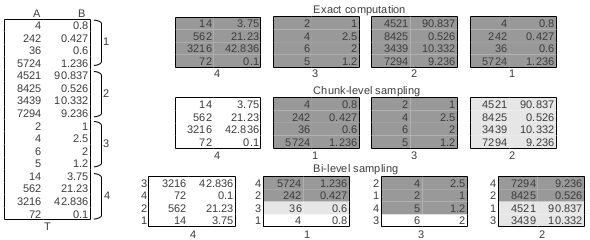
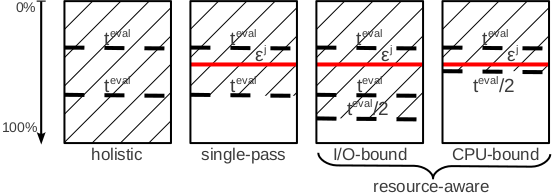
Holistic sampling is a straightforward realization of the bi-level sampling procedure that does not consider how much to sample from a chunk---it samples the entire chunk. However, in order to avoid the inspection paradox and to reduce the interval between estimations, samples are extracted from each chunk at fixed time intervals. We emphasize that this is not chunk-level sampling because any subset of the chunk represents a sample---including the complete chunk. By grouping the samples from all the chunks together, a bi-level sample is generated and an estimate and corresponding confidence bounds can be computed.
Single-Pass Sampling
In single-pass sampling, all the chunks are included in the sample, however, the number of tuples is determined by the intra-chunk variance. We sample all the chunks because this eliminates the inter-chunk variance while preserving the bi-level nature of the sampling process. This constant solution guarantees that more tuples are sampled from chunks with higher variability and less from chunks that are homogeneous. Single-pass sampling is an algorithm to independently sample across chunks that allows for maximum concurrency. It guarantees that -- in the worst scenario when all the chunks are sampled -- the aggregate estimate meets the required accuracy. It is important to emphasize that an estimate can be computed at any instant during the process and the accuracy can be met before all the chunks are considered. This can be done exclusively from the raw data---without knowledge of any other statistical information beyond simple chunk-level tuple counts.
Resource-Aware Sampling
The single-pass sampling strategy guarantees that the required accuracy is met after a pass over the data. While theoretically sound for a worst-case scenario, it does not take into account the runtime conditions. As soon as the local accuracy is satisfied, sampling for the chunk is terminated, even though computational resources may be available. As a result, the opportunity to further reduce the total variance of the estimator is missed. We address this shortcoming by introducing a novel bi-level sampling strategy that dynamically and adaptively determines how much to sample from a chunk by continuously monitoring the resource utilization of the system. While the original goal of single-pass sampling is preserved, we aim to maximize the chunk-level sample size without decreasing the rate at which chunks are processed. In resource-aware sampling, the decision of when to stop sampling from a chunk is based on the availability of system resources -- I/O bandwidth and CPU threads -- in addition to the chunk accuracy. This requires continuous system monitoring at runtime. The cost of monitoring does not incur significant overhead and it allows for the early detection of changes in the workload. As long as the number of threads is larger than the number of chunks in the buffer, processing is I/O-bound. Otherwise, it is CPU-bound. For I/O-bound processing, our goal is to end a chunk as soon as another chunk becomes available and there are no threads in the pool. In the case of CPU-bound tasks, the goal is to finalize a chunk as soon as the accuracy is met.
This project is partially supported by a DOE Early Career Award. The results are published in the following papers:
-
Bi-Level Online Aggregation on Raw Data
by Y. Cheng, W. Zhao, and F. Rusu.
-
OLA-RAW: Scalable Exploration over Raw Data
by Y. Cheng, W. Zhao, and F. Rusu.
UC Merced |
EECS |
Home |
OLA
Last updated: Monday, November 27, 2017