Online Aggregation (OLA)
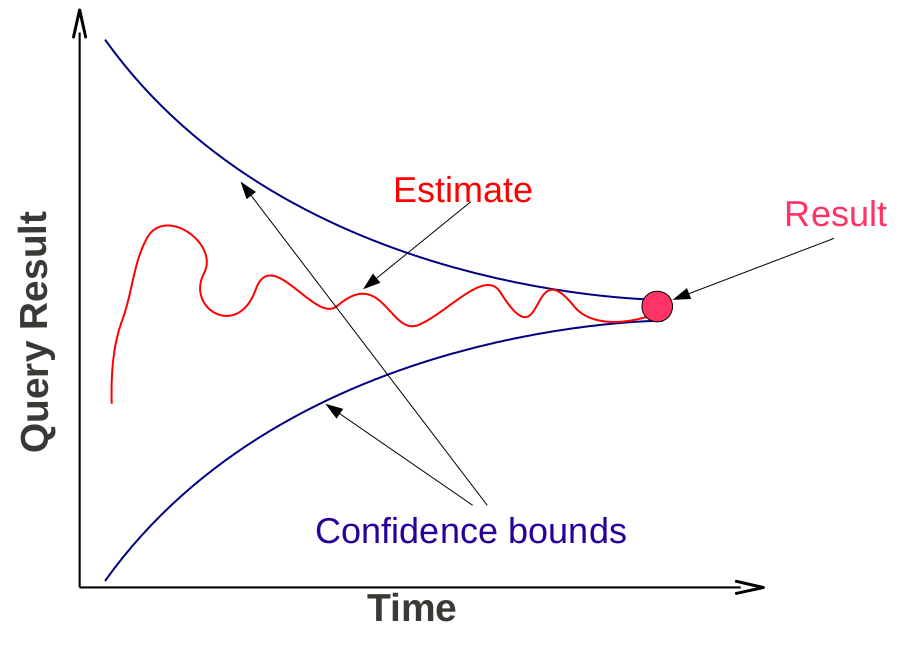
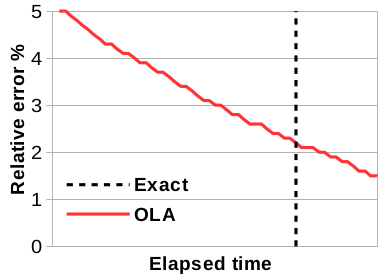
Online aggregation provides continuous estimates to the final result of a computation during the actual processing. The user can stop the computation as soon as the estimate is accurate enough, typically early in the execution, or can let the processing terminate and obtain the exact result. The main idea in OLA is to estimate the query result based on a sample of the data. In addition to the estimator, OLA defines a principled method to derive confidence bounds. The estimator and the bounds are computed from a sample much smaller in size than the overall dataset, thus reducing the query execution time tremendously. Our research on online aggregation dates back to 2007. DBO (2008) and TurboDBO (2009) are sampling systems built for joins over many large tables. In PF-OLA (2013), we tackle OLA in a distributed asynchronous setting where estimation and query processing overlap. We apply OLA to hyper-parameter tuning in gradient descent optimization (2015) and design two algorithms -- Approximate BGD and Approximate IGD -- with faster convergence. OLA-RAW (2017) is an OLA framework over raw data based on bi-level sampling.
UC Merced |
EECS |
Home
Last updated: Monday, November 27, 2017