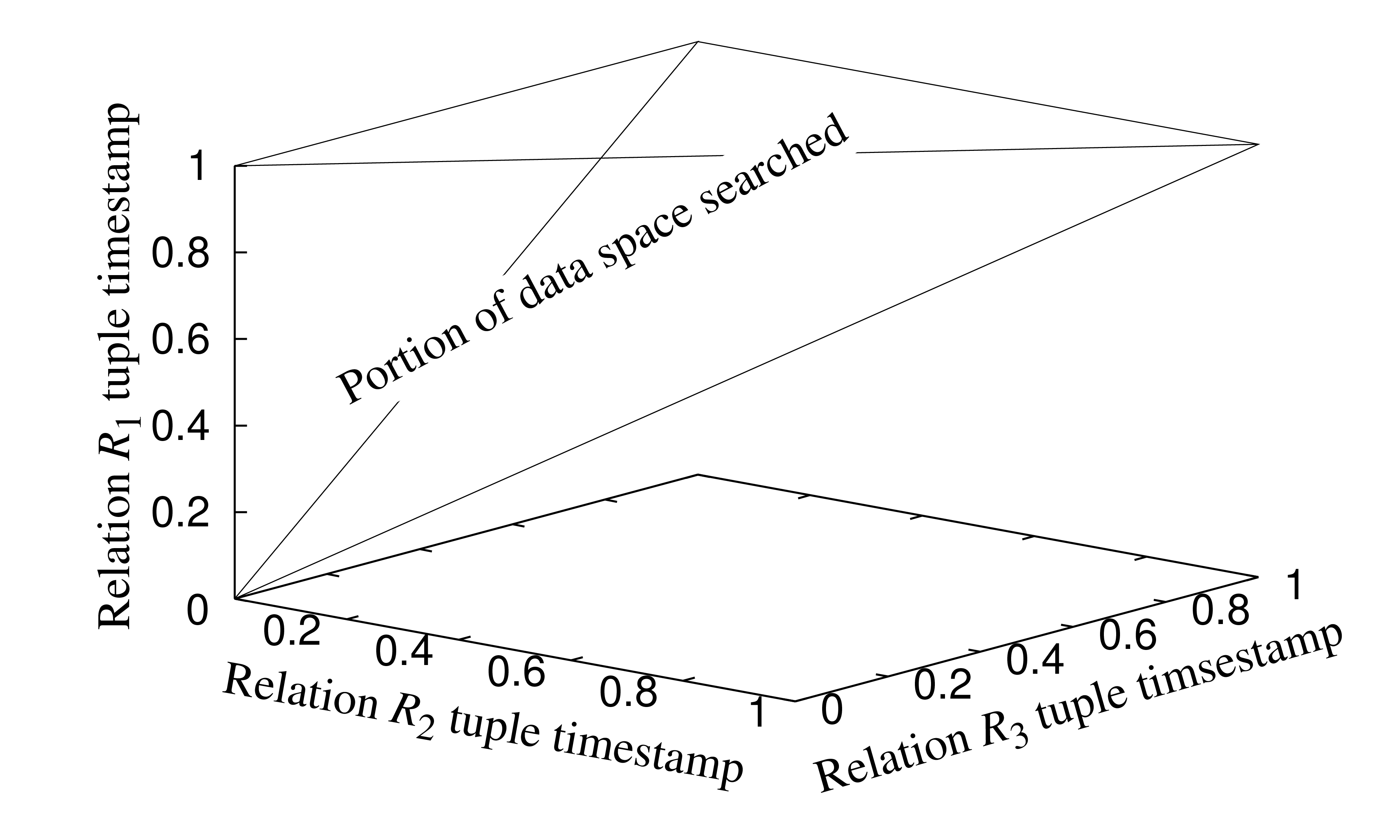DBO & TurboDBO
DBO
DBO is designed to facilitate interactive analytic processing over the largest databases. Like traditional relational database systems, DBO can produce exact answers in a scalable fashion. However, unlike any existing research or production system, DBO uses randomized algorithms to produce a statistically meaningful guess for the final query answer at all times throughout query execution. The guess is always bounded by approximation guarantees, such as "With a probability of 95%, the true answer is between 12.2 and 13.6". As more data are processed, the guess is made more and more accurate. A user can stop execution whenever satisfied with the guess' accuracy, which may translate to dramatic time savings during exploratory processing, or else he/she can run the query to completion. In this way, DBO can render interactive, ad-hoc analytic query processing a reality, even over the largest databases.
In designing DBO, the goal is to achieve scalability in analytic processing, while at the same time always giving the user an accurate guess for the final answer to a query. To realize this, the various relational operators running within the DBO engine are constantly communicating with one another, checking whether tuples produced as partial query result can combine to form tuples that will actually appear in the query result set. Since tuples are always processed in a statistically random (or pseudo-random) order, whether or not DBO is "lucky" enough to find such tuples can be used to provide for a statistically meaningful guess for the final answer to the underlying query.
Building DBO has posed two sets of fundamental challenges: one set related to the nearly total database system redesign that is required and second set related to the resulting statistical issues. Classic database system design cannot support the randomized algorithms required by DBO because traditionally, relational operations run in isolation, and do not share internal state. The statistical challenges presented by DBO are significant because of the difficulty of analyzing the effect of DBO's randomized algorithms on joins, set subtractions, and other operations.
Traditionally, query processing operations such as joins and table scans operate in isolation as black boxes with little or no communication of their internal state to the outside world. In contrast, in DBO all operations constantly communicate internal state in order to facilitate the search for "lucky" output tuples. The reason for this requirement is clear: if a query involves multiple relations, it is impossible to guess the answer if we exclude information provided by an operation that is exclusively processing one of the relations. It is for this reason that query processing in DBO is centered around the basic abstraction of a levelwise step. A levelwise step consists of all of the operations that are performed at a single level of a query plan. It provides for communication of internal state so that "lucky" tuples can be located, and it allows careful control of the progress of the underlying relational operations so that the statistical properties of the search for "lucky" tuples can be characterized mathematically.

There are five major software components in the DBO system:
- Query Compiler
- Controller
- Levelwise Step Module
- In-Memory Join
- Statistics Module
These components work together to evaluate a query as follows. Before query execution begins, the query compiler compiles the query and uses the resulting query plan to create instances of the four query processing components: the controller, the required levelwise steps, the in-memory join, and the statistics module. After this startup phase, control of query processing is passed to the controller. The controller directs data flow throughout the system, and makes sure that all software components operate in a synchronized fashion.
In DBO, one output thread is associated with each relational operation. These threads place output tuples into data pipelines that send the tuples into the next levelwise step. Conceptually, the controller places a "blockage" into each of the output pipes from the current levelwise step. This blockage allows the operations in the step to continue their operation until they produce enough output tuples that the pipeline "backs up" and then each blocked operation must wait until the blockage on its pipe is removed by the controller.
When the controller is ready to process more data, it temporarily removes the blockage from one of the output pipes. This allows a set of random tuples to flow into the next levelwise step, where they are processed. A fork in the pipeline also directs copies of those tuples into the controller, where they are forwarded into the in-memory join. It is the task of the in-memory join to efficiently look for any "lucky" output tuples that happen to contribute to the final query result. The in-memory join buffers random subsets of each of the output relations from the current levelwise step in a set of hash table indexes. When the in-memory join receives a new set of tuples from one of the output relations, it discards the old set from that output relation and replaces it with the new tuples. The in-memory join then uses the hashed index to efficiently join all of the buffered tuples; the result of this in-memory join is then sent to the controller.
The controller then forwards those lucky output tuples to the statistics module, where they are used to update the current estimate for the query result, as well as
to update the statistical model for the variance (or inaccuracy) of the current estimate. After this, the statistics module updates the user interface with the current estimate. The controller then uses information from the statistics module to decide which pipe to unblock next (and for how long) in order to speed convergence.

A more detailed description of the DBO system and design diagrams can be found in the following documents:
-
The DBO Database System
by F. Rusu et al.
-
The DBO Database System: Poster
by F. Rusu et al.
TurboDBO
The utility of the DBO system should ultimately be measured by its ability to quickly provide tight bounds on the final query result. That is, DBO should have a short "time 'til utility" (TTU). If the bounds that DBO supplies are wide even after much of the query plan has been processed, then the ability to provide an estimate will be of little use, because the estimate is of poor quality. In practice, we have found that DBO often works quite well, though there is a class of queries where DBO's convergence to the actual query result can be too slow for comfort:
- Highly-selective queries
- Queries over skewed data
- Multi-join queries
Turbo DBO is built using the same software architecture as DBO. In order to reduce TTU for the problematic queries, Turbo DBO uses a different estimation process centered on partial result tuples or partial matches, which results in a significant boost in estimation accuracy---confidence bounds that are orders of magnitude
smaller than the ones produced by DBO. This requires a complete rewriting of the in-memory join and estimation modules in the original DBO to incorporate several novel techniques, such as an optimized building order for partial matching tuples, a sub-sampling process to control memory usage, and a tuple "timestamping" abstraction to control the randomization in the system.
The difference between DBO's and Turbo DBO's estimation processes is presented in the above images which show the search space for "lucky" tuples employed by each system. For more technical details on Turbo DBO and a comprehensive comparison of the two estimation processes, consult the following document:
-
Turbo-Charging Estimate Convergence in DBO
by A. Dobra, C. Jermaine, F. Rusu, and F. Xu
The code implementing the DBO architecture with the two different estimation processes can be downloaded here. Notice that the code is not "pretty" and there are not a lot of comments to guide you. If you feel like you want to give it a try, the README file inside the package is a good starting point. And if you find any bugs or need help, do not hesitate to email me.
UC Merced |
EECS |
Home |
OLA
Last updated: Monday, November 27, 2017