Scalable Gradient Descent Optimization (SGD)
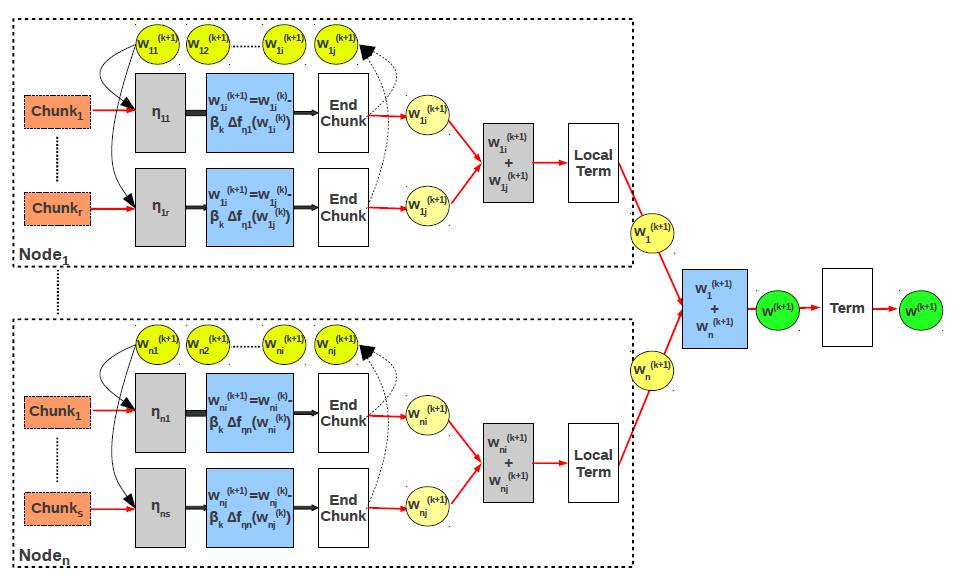
We have become interested in gradient descent optimization because of the observation that this method can be easily implemented in GLADE using the GLA interface. This initial work from 2012 shows how to efficiently implement stochastic gradient descent (SGD) with support for both multi-thread and distributed processing. Due to the major role gradient descent plays in ML model training and AI, our interest has grown over the years. We introduce a hybrid low-rank factorization (LMF) algorithm (2013) that combines asynchronous local updates with coordinated distributed partitioning to minimize overall model conflicts. We propose SGD hyper-parameter tuning methods based on approximate computing with online aggregation (2014). These methods decrease the time to convergence tremendously by searching the hyper-parameter space more thoroughly. We introduce the dot-product join database operator (2015) for computing dot-products between highly-dimensional vectors. Dot-product is the most important primitive in model training and prediction, as exemplified by the specialized hardware built specifically for this operation in Google's Tensor Processing Unit (TPU) and NVIDIA GPUs. We then extend the dot-product join operator to the asynchronous Hogwild SGD algorithm (2017). We also investigate the speedup provided by implementing gradient descent optimization in-memory (2016) using a PIM framework. Our most recent work on this topic compares SGD on multi-core CPU and GPU (2019) for generalized linear models and deep neural networks.
UC Merced |
EECS |
Home
Last updated: Thursday, July 25, 2019