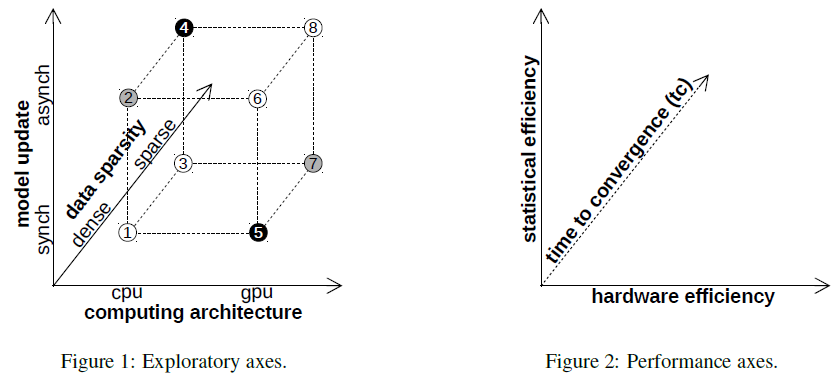
Exploratory axes. On the computing architecture axis, we consider multi-core CPUs with Non-Uniform Memory Access (NUMA) and many-core GPUs with wide Single Instruction Multiple Data (SIMD) processing units. The model update strategies we consider are synchronous and asynchronous. Synchronous updates follow a transactional semantics and allow a single thread to update the model. While this strategy limits the range of parallel execution inside the SGD algorithm, it is suitable for batch-oriented high-throughput GPU processing. In the asynchronous strategy, multiple threads update the model concurrently. Our focus is on the Hogwild algorithm which ignores any synchronization to the shared model. Data sparsity represents the third axis. At one extreme, we have dense data in which there is a non-zero entry for each feature in every training example. This allows for a complete dense 2-D matrix representation. When the model is large, it is often the case that the examples have only a few non-zero features. A sparse matrix format, e.g., Compressed Sparse Row (CSR), is the only alternative that fits in memory in this case. The majority of the GPU solutions implement synchronous model updates over dense data, while the CPU implementations use asynchronous Hogwild which is suited for sparse data. In this paper, we explore the complete space and map the remaining combinations. We design an efficient Hogwild algorithm for GPU that is carefully tuned to the underlying hardware architecture, the SIMD execution model, and the deep GPU memory hierarchy. The considerably larger number of threads available on the GPU and their complex memory access pattern pose significant data management challenges in achieving an efficient implementation with optimal convergence. The Hogwild GPU kernel considers data access path and replication strategies for data and the model to identify the optimal configuration for a given task-dataset input. Moreover, we introduce specific optimizations to enhance the coalesced memory access for SIMD processing. Synchronous SGD on CPU turns out to be a simplification of the GPU solution. Instead of executing the linear algebra kernels on the GPU, invoke functions on the CPU. This is easily achieved by using computational libraries with dual CPU and GPU support. Since the CPU functions do not require data transfer, they have the potential to outperform a sequence of GPU kernels that are not cross-optimized. The massive number of powerful threads in our testbed CPU provides an additional boost in performance.
Performance axes. The hardware efficiency measures the average time to do a complete pass - or iteration - over the training examples. Ideally, the larger the number of physical threads, the shorter an iteration takes since each thread has less data to work on - thus, higher hardware efficiency. In practice, though, this holds only when there is no interaction between threads - even then, the size and location of data can be limiting factors. In asynchronous SGD, however, the model is shared by all (or a group of) the threads. This poses a difficult challenge both in the CPU and GPU case. For CPU, the implicit cache coherency mechanism across cores can decrease the hardware efficiency dramatically. Non-coalesced memory accesses inside a SIMD unit have the same effect on GPU. The statistical efficiency measures the number of passes over the data until a certain value of the loss function is achieved, e.g., within 1% of the minimum. This number is architecture-independent for synchronous model updates which are executed at the end of each pass. In the case of asynchronous model updates during a data pass, however, the number and order of updates may have a negative impact on the statistical efficiency. The third performance axis is represented by the time to convergence. This is, essentially, the product between the hardware and statistical efficiency. The reason we include it as an independent axis is because there are situations when two algorithms have reversed hardware and statistical efficiency - algorithm A has better hardware efficiency than algorithm B and worse statistical efficiency - and only the time to convergence allows for a full comparison. Such a case is common for synchronous and asynchronous updates and for CPU and GPU execution, respectively.
Summary of results.