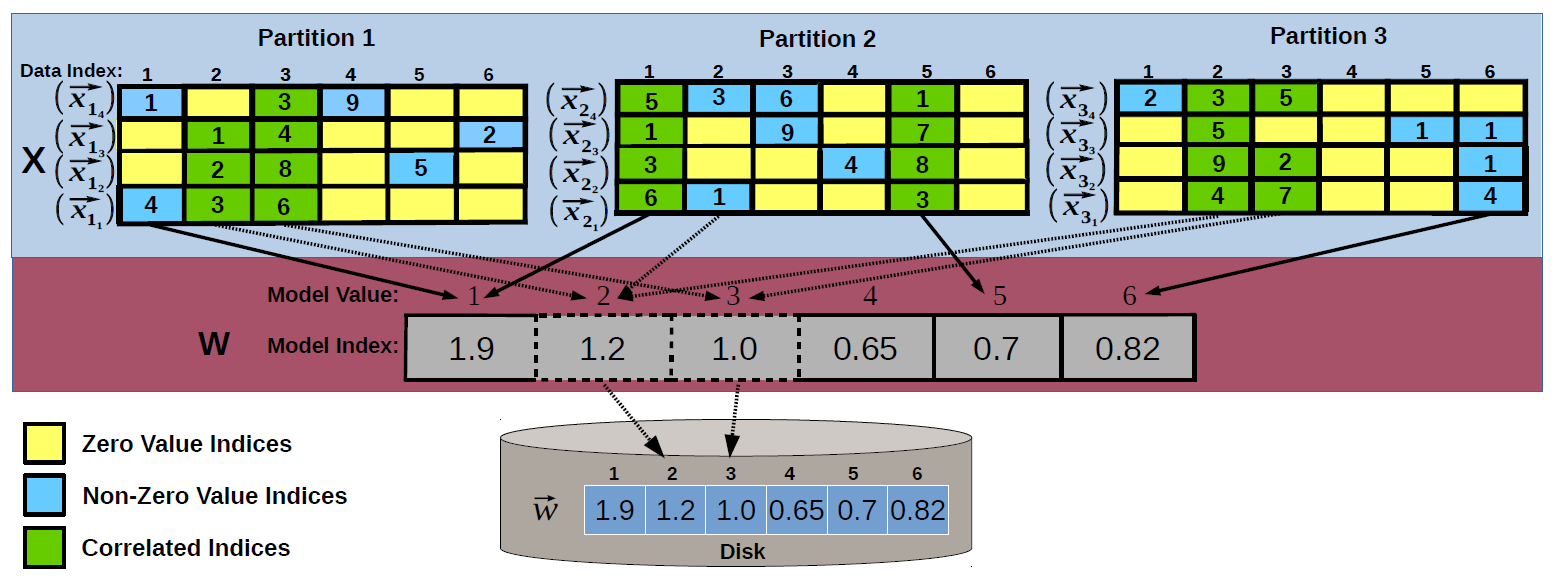
While extending HOGWILD! to disk-resident models is straightforward, designing a truly scalable algorithm that supports model and data-parallel processing is a considerably more challenging task. At a high-level, our approach targets the main source that impacts performance - the massive number of concurrent model accesses - with two classical database processing techniques - vertical partitioning and model access sharing. The model is vertically partitioned offline based on the concept of feature occurrence such that features that co-occur together require a single model access. Feature co-occurrence is a common characteristic of big models in many analytics tasks. It is important to notice that feature co-occurrence is fundamentally different from the feature correlation that standard feature engineering processes try to eliminate. During online training, access sharing is maximized at several stages in the processing hierarchy in order to reduce the number of disk-level model accesses. The data examples inside a chunk are logically partitioned vertically according to the model partitions generated offline. The goal of this stage is to cluster together accesses to model features even across examples - vertical partitioning achieves this only for the features that co-occur in the same example. In order to guarantee that access sharing occurs across partitions, we introduce a novel push-based mechanism to enforce sharing by vertical traversals of the example data and partial dot-product materialization. Workers preemptively push the features they acquire to all the other threads asynchronously. This is done only for read accesses. The number of write accesses is minimized by executing model updates at batch-level, rather than for every example. This technique is shown to dramatically increase the speedup of HOGWILD! for memory-resident models because it eliminates the pingpong effect on cache-coherent architectures. We design a scalable model and data-parallel framework for parallelizing stochastic optimization algorithms over big models. The framework organizes processing in two separate stages - offline model partitioning and asynchronous online training. We formalize model partitioning as vertical partitioning and design a scalable frequency-based model vertical partitioning algorithm. The resulting partitions are mapped to a novel composite key-value storage scheme. We devise an asynchronous method to traverse vertically the training examples in all the data partitions according to the model partitions generated offline. We design a push-based model sharing mechanism for incremental gradient computation based on partial dot-products. We implement the entire framework using User-Defined Aggregates (UDA) which provides generality across databases.
We design a novel model and data-parallel SGD framework specifically optimized for disk-based key-value stores. We take advantage of index correlation in both how the model is stored on disk and how it is concurrently accessed across threads. There are two stages in the scalable HOGWILD! framework.
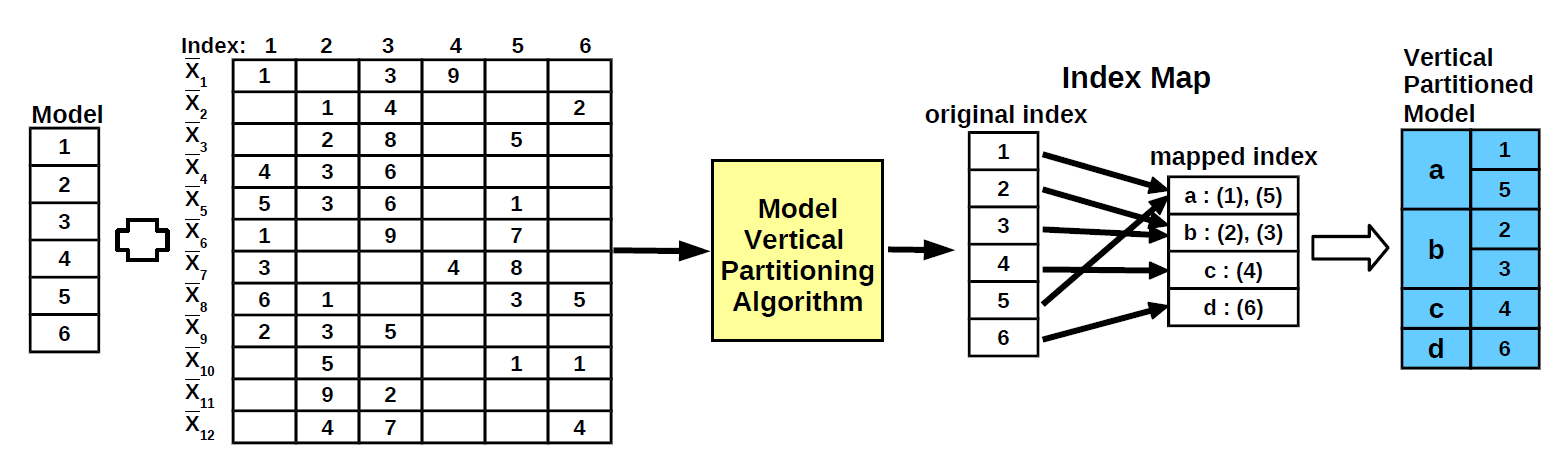
The offline stage aims to identify index correlations in the training dataset in order to generate a correlation-aware model partitioning that minimizes the number of get/put requests to the key-value store. Existing solutions do not consider index correlation for storing and organizing the model on disk. They fall in two categories. In the first case, each index is assigned an individual key that is retrieved using the key-value store get/put interface. This corresponds to columnar partitioning and incurs all the limitations of the naive HOGWILD! extension. Range-based partitioning is the other alternative. In this case, indices that are adjacent are grouped together. However, this partitioning does not reflect the correlated indices in the training dataset. We propose a novel solution to find the optimal model partitioning by formalizing the problem as the well-known vertical partitioning in storage access methods.
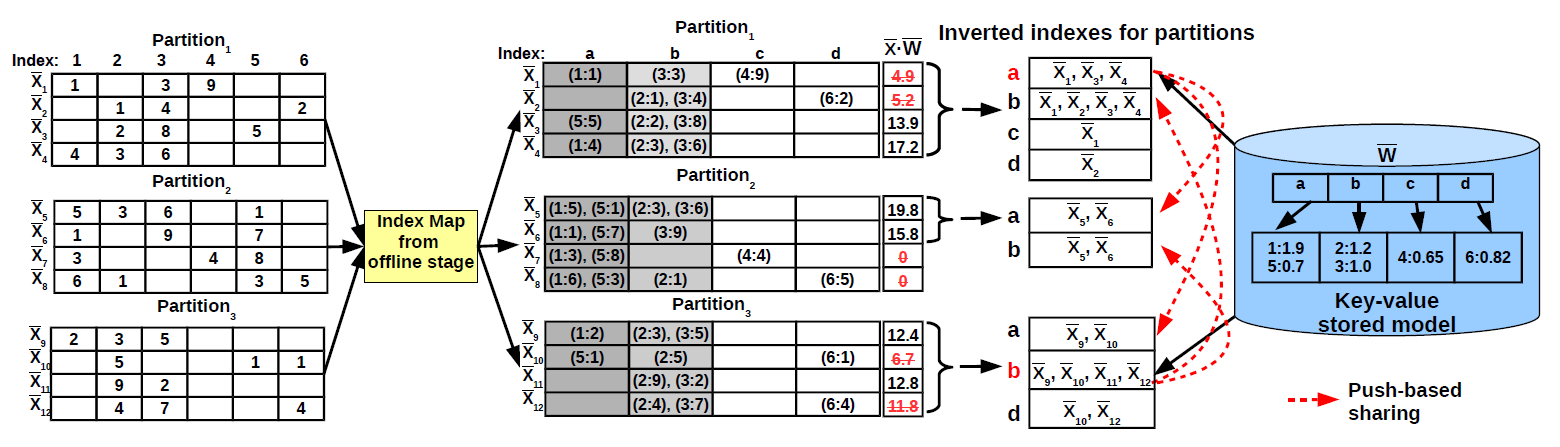
In the online training stage, the model partitioning is used to maximize access sharing across threads in order to reduce the number of disk-level model accesses. Data and model partitioning facilitate complete asynchronous processing in online training. The partitions over examples are processed concurrently and themselves access the model partitions generated in the offline stage concurrently. This HOGWILD! processing paradigm - while optimal in shared-memory settings - is limited by the disk access latency in the case of big models. Model partitioning alone reduces the number of accesses for the correlated indices inside a training example. However, it does not address correlated index accesses across examples and across threads. The order in which requests are made plays an important role in enhancing cache locality. The same reasoning also applies to the examples inside a partition. At a first look, coordinating model access across partitions seems to require synchronization between the corresponding threads. This is not the case. We devise an asynchronous solution that traverses the training examples in all the data partitions vertically, according to the model partitions generated offline. This enhances cache locality by allowing the same model index to be used by all the examples inside a partition. In order to guarantee access sharing across partitions, we design an asynchronous mechanism in which partitions preemptively push the indices they acquire to all the other concurrent partitions. This is done only for get accesses.