Array Views
We introduce the concept of materialized array views defined over complex shape-based similarity join aggregate queries. Since shape-based array similarity join is a generalization of array equi-join and distance-based similarity join, materialized array views cover an extensive class of array algebra operations. With regard to SQL, array views include the class of join views with standard aggregates. We tackle incremental array view maintenance under batch updates to the base arrays. Batch updates are the only form of updates in many real applications, e.g., astronomy, and are essential for amortizing the cost of network communication and synchronization in a distributed deployment which is the case for array databases. There are two primary challenges posed by incremental array view maintenance under batch updates. The first challenge is identifying the cells in the base array(s) that are involved in the maintenance computation and the cells that require update in the array view. This is a problem because of the complex query in the view definition which involves a shape-based similarity join. Enumerating all the cells in the shape array corresponding to an update can be expensive for large shapes and sparse arrays. The second challenge is due to the distributed nature of array databases. Given the current distribution of the array(s) and the view, the challenge is to find the optimal strategy - data transfer and computation balancing - to integrate the updates into the view. Direct application of distributed relational view maintenance algorithms to arrays suffers from excessive communication and load imbalance due to the static array partitioning strategies and the skewed distribution of the updates in scientific applications. Since the granularity of I/O and computation in array databases is the chunk, the first challenge requires only the identification of the chunks involved in view maintenance. This can be done efficiently as a preprocessing step over the metadata. Our approach for the second challenge is to model distributed array view maintenance as an optimization formulation that computes the optimal plan to update the view based on the chunks identified in preprocessing. Moreover, the optimization continuously repartitions the array and the view based on a window of past batch updates. In the long run, repartitioning improves view maintenance time by grouping relevant portions of the array and the view and by distributing join computation across the cluster. Meanwhile, repartitioning does not incur additional time because it takes advantage of the communication required in view maintenance. Since the optimization cannot be solved efficiently, we decompose the formulation into three separate stages - differential view computation, view chunk reassignment, and array chunk reassignment - that we solve independently.
Array views have a major impact in astronomy. They have been incorporated in the Palomar Transient Factory (PTF) pipeline and played a pivotal role in the first-ever observation of a neutron star merger which produces gravitational waves and turns out to be the origin of heavy elements, including gold. This lead to a Science magazine article (complete manuscript on arXiv) featured in the media at UC Merced, DOE ASCR, ACM TechNews, Slashdot, FiveThirtyEight, Quanta Magazine, etc.
This project is supported by a DOE Early Career Award. The results are published in the following papers:
-
iPTF Archival Search for Fast Optical Transients
by A. Ho, S. R. Kulkarni, P. Nugent, W. Zhao, F. Rusu, S. B. Cenko, V. Ravi, M. M. Kasliwal, D. A. Perley, S. M. Adams, E. C. Bellm, P. Brady, C. Fremling, A. Gal-Yam, D. Kann, D. Kaplan, R. R. Laher, F. Masci, E. O. Ofek, J. Sollerman, and A. Urban
-
Illuminating Gravitational Waves: A Concordant Picture of Photons from a Neutron Star Merger
by M. M. Kasliwal, E. Nakar, L. P. Singer, D. L. Kaplan, D. O. Cook, A. Van Sistine, R. M. Lau, C. Fremling, O. Gottlieb, J. E. Jencson, S. M. Adams, U. Feindt, K. Hotokezaka, S. Ghosh, D. A. Perley, P.-C. Yu, T. Piran, J. R. Allison, G. C. Anupama, A. Balasubramanian, K. W Bannister, J. Bally, J. Barnes, S. Barway, E. Bellm, V. Bhalerao, D. Bhattacharya, N. Blagorodnova, J. S. Bloom, P. R. Brady, C. Cannella, D. Chatterjee, S. B. Cenko, B. E. Cobb, C. Copperwheat, A. Corsi, K. De, D. Dobie, S. W. K. Emery, P. A. Evans, O. D. Fox, D. A. Frail, C. Frohmaier, A. Goobar, G. Hallinan, F. Harrison, G. Helou, T. Hinderer, A. Y. Q. Ho, A. Horesh, W.-H. Ip, R. Itoh, D. Kasen, H. Kim, N. P. M. Kuin, T. Kupfer, C. Lynch, K. Madsen, P. A. Mazzali, A. A. Miller, K. Mooley, T. Murphy, C.-C. Ngeow, D. Nichols, S. Nissanke, P. Nugent, E. O. Ofek, H. Qi, R. M. Quimby, S. Rosswog, F. Rusu, E. M. Sadler, P. Schmidt, J. Sollerman, I. Steele, A. R. Williamson, Y. Xu, L. Yan, Y. Yatsu, C. Zhang, and W. Zhao
-
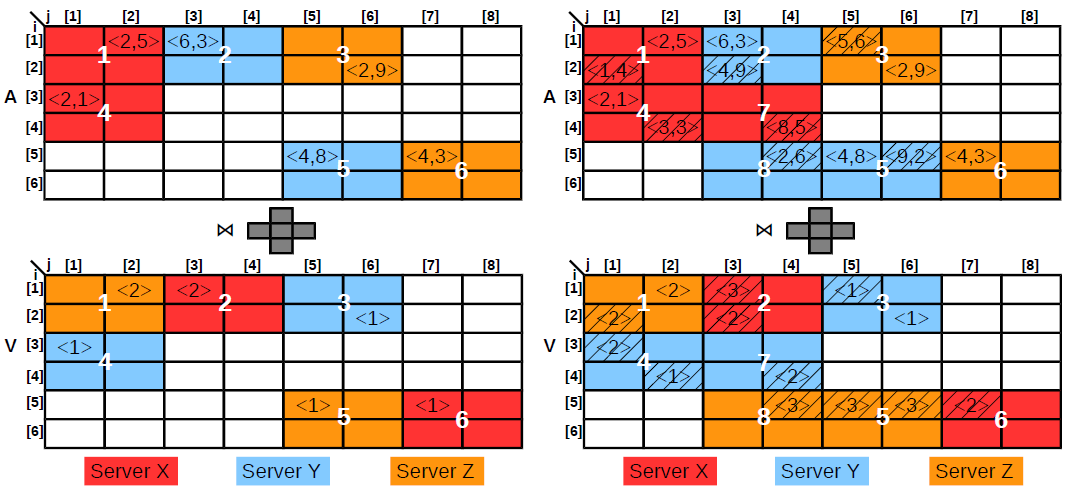
Incremental View Maintenance over Array Data
by W. Zhao, F. Rusu, B. Dong, K. Wu, and P. Nugent
UC Merced |
EECS |
Home |
Array Databases
Last updated: Friday, December 15, 2017