Robust Visual Tracking via Convolutional Networks without Training
Kaihua Zhang Qingshan Liu Yi Wu Ming-Hsuan Yang
Abstract
Deep networks have been successfully applied to visual tracking by learning a generic representation offline from numerous training images. However, the offline training is timeconsuming and the learned generic representation may be less discriminative for tracking specific objects. In this paper we present that, even without offline training with a large amount of auxiliary data, simple two-layer convolutional networks can be powerful enough to learn robust representations for visual tracking. In the first frame, we employ the k-means algorithm to extract a set of normalized patches from the target region as fixed filters, which integrate a series of adaptive contextual filters surrounding the target to define a set of feature maps in the subsequent frames. These maps measure similarities between each filter and useful local intensity patterns across the target, thereby encoding its local structural information. Furthermore, all the maps together form a global representation based on mid-level features and hence the inner geometric layout of the target is also preserved. A simple soft shrinkage method with an adaptive threshold is used to de-noise the global representation and generate a robust sparse representation. The representation is updated via a simple and effective online strategy, allowing it to robustly adapt to target appearance variations. Our convolutional networks have lightweight structure and perform favorably against several state-of-the-art methods on the recent tracking benchmark dataset with 50 challenging videos.
Overview of our approach
|
|
|
Figure 1. Overview of our method. Input samples are warped into a canonical 32x32 images. We first use the k-means algorithm to extract a set of normalized local patches from the warped target region in the first frame, and extract a set of normalized local patches from the contextual region surrounding the target. We then use them as filters to convolve each normalized sample extracted from subsequent frames, resulting in a set of feature maps. Finally, the feature maps are de-noised by a soft shrinkage method, which results in a robust sparse representation. |
Experimental Results
Datasets:
For experimental validation, we use the tracking benchmark dataset and code
library [7] which includes 29 trackers and 50 fully-annotated videos (more
than 29,000 frames). In addition, we also add the results of two
state-of-the-art trackers including the KCF [11], TGPR [12], and DLT [6]
methods.
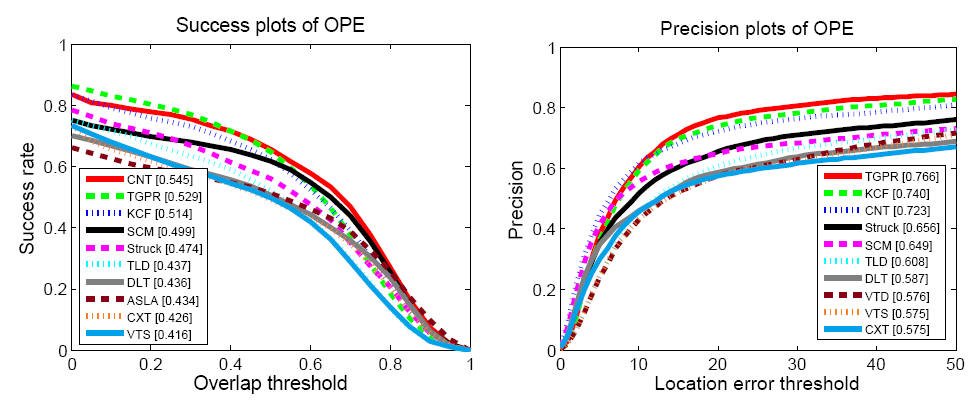
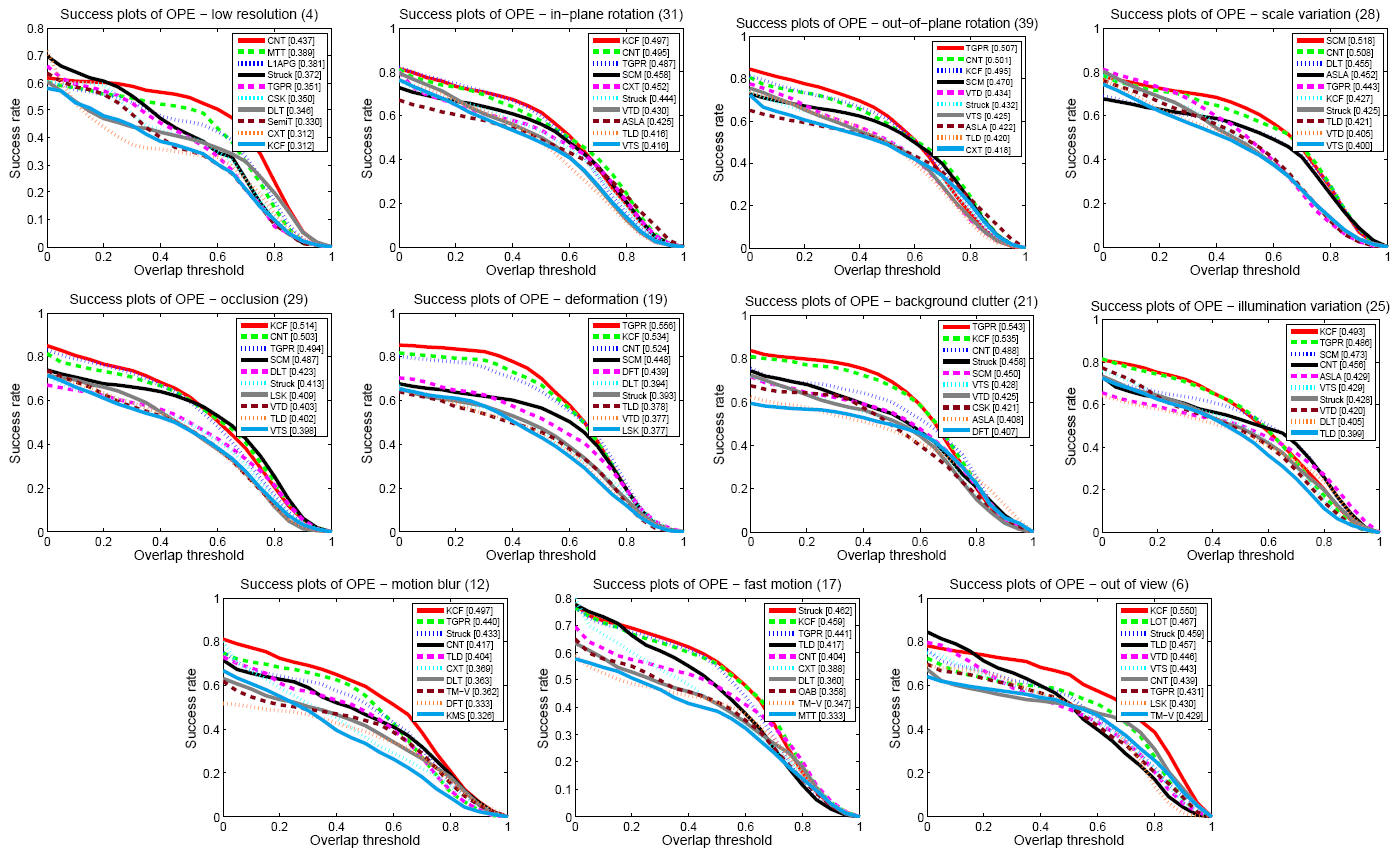
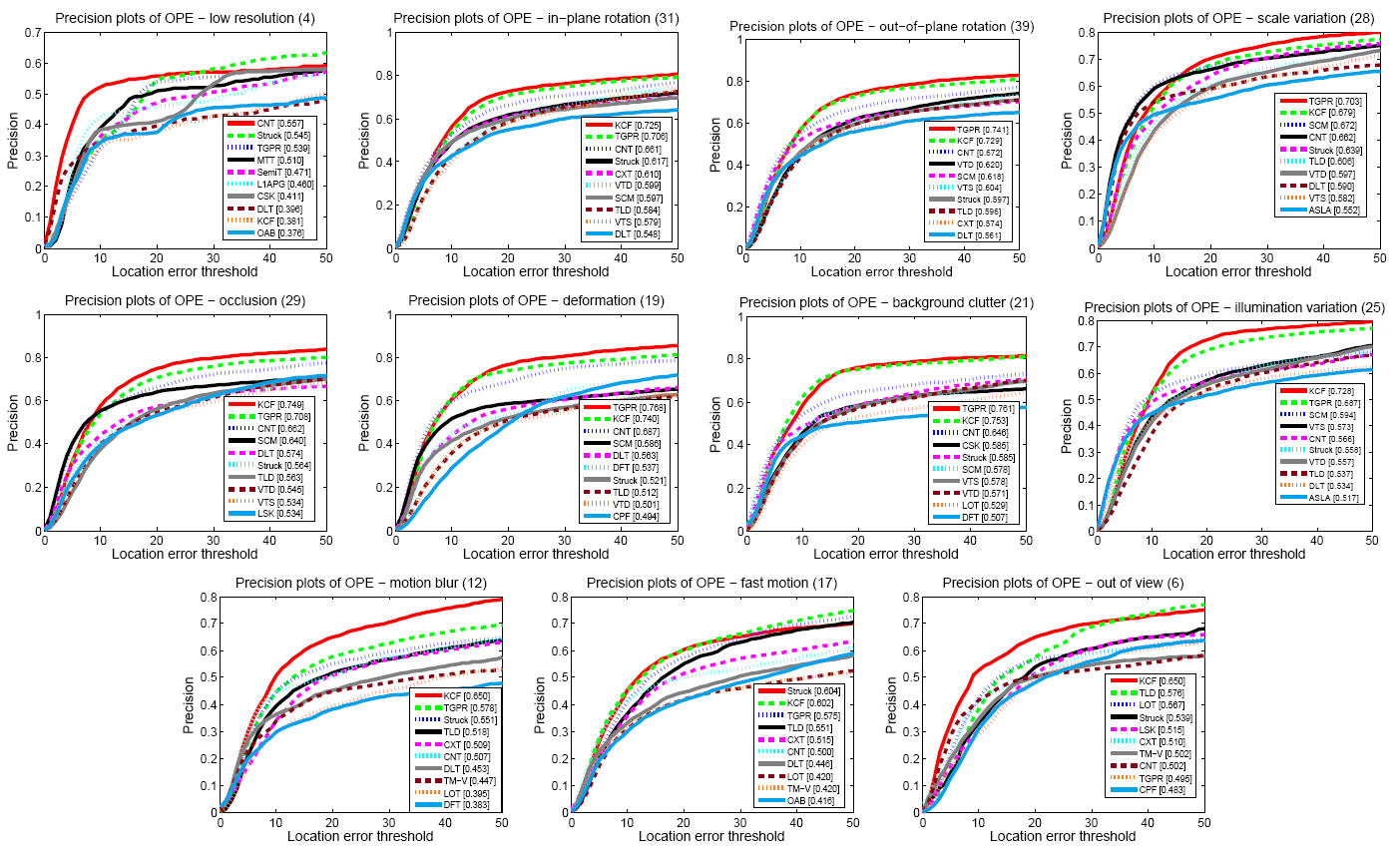
Figure 2 shows the success and precision plots of OPE of the top 10 performing tracking methods. Overall, the proposed CNT algorithm performs well against the state-of-the-art tracking methods. We analyze the tracking performance based on 11 challenging attributes of object tracking [7]. Overall, the CNT method performs well in all attributebased evaluation against the state-of-the-art methods.
|
|
|
|
Figure 2 - The success plots and precision plots of OPE for the top 10 trackers. The performance score of success plot is the AUC value while the performance score for each tracker is shown in the legend. The performance score of precession plot is at error threshold of 20 pixels. |
|
|
|
|
|
Figure 3 - The success plots of videos with different attributes. |
|
|
|
|
|
Figure 4 - Precision plots of videos with different attributes. |
|
Related Publication
Robust Visual Tracking via Convolutional
Networks without Training
|
Video Tracking Results
We show tracking results of 50 challenging videos.
