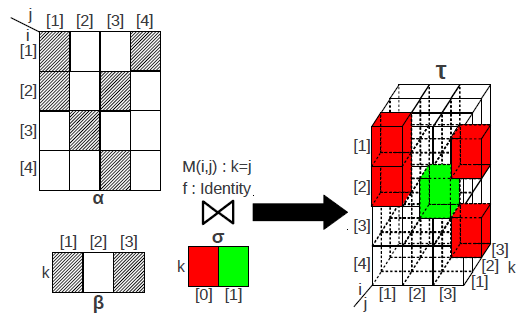
 |
 |
|
|
The array similarity join operator functions as follows. The user submits a query to the coordinator node in charge of managing the workers and the metadata catalog. The coordinator computes an optimal execution plan for the query and sends it to the worker nodes. The workers process their share of chunks concurrently and asynchronously, informing the coordinator only when they finish. The execution of the array similarity join operator follows closely the structural join. The most significant difference is that the node which computes the join between two chunks is determined in the query optimization process - it is not the node that stores the chunk. As a result, although the schema of the output array is well-defined at query time, its chunking is known only at query execution. The actual shape of the chunks is determined by the shape array in the query. The array similarity join operator overlaps I/O - disk and network - with join computation at chunk granularity. Network transfer and local disk I/O are each handled by a separate thread. The join between two chunks is executed in a separate worker thread. The operator is configured with a pool of worker threads, allocated based on the number of CPU cores available in the system. Thus, several joins between pairs of chunks can be executed concurrently. All the threads - I/O and workers - execute asynchronously and coordinate through message exchange. The extensive degree of parallelism puts additional pressure on the I/O components - network, in particular - and makes their optimization even more critical. Thus, minimizing data transfer and network congestion are the primary objectives in the optimization of the array similarity join operator.
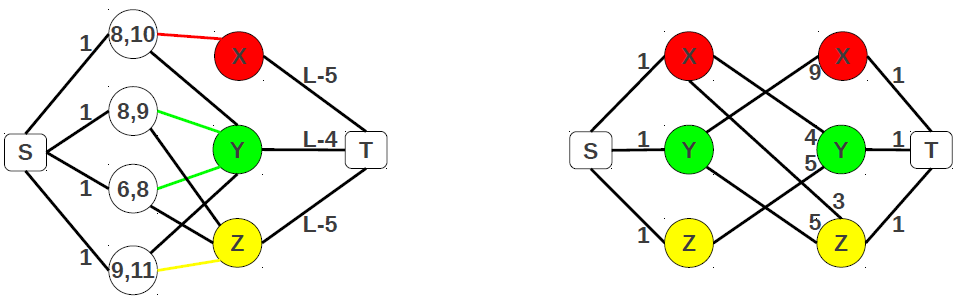 |
The coordinator is responsible for computing the optimal execution plan that minimizes the overall query processing time. The optimal plan is computed exclusively from the array similarity join query and the catalog metadata which stores the location of the chunks and relevant chunk statistics, such as the number of non-empty cells. The global plan consists of a detailed execution sub-plan for each of the worker nodes. The transfer graph specifies the chunks and the nodes where to send them, and the chunks to be received and from which nodes, respectively. The transfer schedule gives the order in which to send/receive chunks. It has two components: 1) the order of the nodes and 2) the order of the chunks assigned to a node. The optimal transfer schedule minimizes network congestion by enforcing only pairs of nodes to exchange data at any instant in time - a node receives data from a single other node. The data access plan specifies the order in which to access local chunks when joining them with remote chunks. Since a local chunk joins with several remote chunks and a remote chunk joins with several local chunks, reducing I/O traffic - the assumption is that not all the local chunks fit in memory - plays an important role in minimizing query processing time.
UC Merced | EECS | Home | Array Databases